Оптическое сканирование это: Что такое оптическое распознавание символов? — AWS
Содержание
Что такое оптическое распознавание символов? — AWS
Что такое оптическое распознавание символов?
Оптическое распознавание символов (OCR) – это процесс преобразования изображения текста в машиночитаемый текстовый формат. Например, при сканировании бланка или квитанции, компьютер сохраняет скан в виде файла изображения. Текстовый редактор невозможно использовать для редактирования, поиска или подсчета слов в файле изображения. OCR помогает преобразовать изображение в текстовый документ, содержимое которого хранится в виде текстовых данных.
В чем заключается важность OCR?
Большинство рабочих процессов связано с получением информации из печатных изданий. Любой бизнес-процесс предусматривает бланки, счета, отсканированные юридические документы и контракты, напечатанные на бумажном носителе. Такие большие объемы бумажной работы требуют много времени и места для хранения и обработки. Хотя безбумажный документооборот — это путь вперед, сканирование документа в изображение создает определенные трудности. Этот процесс требует ручного вмешательства и может быть утомительным и медленным.
Этот процесс требует ручного вмешательства и может быть утомительным и медленным.
При оцифровке содержимого документа создаются файлы изображений со скрытым в них текстом. Программы обработки текста не могут обработать текст в изображениях. Технология OCR решает эту проблему путем преобразования изображения в текстовые данные, которые могут быть проанализированы офисным ПО. Затем такие данные можно использовать для аналитики, оптимизации операций, автоматизации процессов и повышения производительности.
Как работает OCR?
Технология OCR включает следующие этапы:
Получение изображения
Сканер считывает документы и преобразует их в двоичные данные. ПО OCR анализирует отсканированное изображение и классифицирует светлые области как фон, а темные — как текст.
Предварительная обработка
Чтобы подготовить текст к распознаванию, ПО OCR очищает изображение и удаляет ошибочные области. Применяются следующие методы очистки:
- Выравнивание и устранение уклона отсканированного документа для облегчения распознавания.

- Сглаживание контраста или удаление пятен цифрового изображения и сглаживание краевых эффектов текстовых изображений.
- Стирание рамок и линий на сканированном изображении.
- Распознавание шрифтов для многоязычной технологии OCR
Распознавание текста
Существует два основных типа алгоритмов OCR или программных процессов, которые использует ПО OCR для распознавания текста: сопоставление шаблонов и выделение признаков.
Сопоставление шаблонов
Сопоставление шаблонов работает путем выделения изображения символа, называемого глифом, и сравнения его с аналогичным глифом, хранящимся в памяти. Распознавание образа произойдет только в том случае, если шрифт и масштаб хранящегося глифа совпадают со шрифтом и масштабом отсканированного глифа. Данный метод эффективен при работе со сканами документов, набранных известным шрифтом.
Выделение признаков
Выделение признаков разбивает или раскладывает глифы на такие признаки, как линии, замкнутые контуры, направление линий и пересечения линий. Затем признаки используются для поиска наилучшего или ближайшего подходящего соответствия среди различных хранящихся глифов.
Затем признаки используются для поиска наилучшего или ближайшего подходящего соответствия среди различных хранящихся глифов.
Окончательная обработка
После анализа система преобразует извлеченные текстовые данные в компьютерный файл. Некоторые системы OCR могут создавать аннотированные PDF-файлы, включающие как предыдущую, так и последующую версии отсканированного документа.
Какие виды OCR существуют?
Специалисты по анализу данных классифицируют различные виды технологий OCR на основе их использования и применения. Ниже представлены лишь некоторые примеры:
Программы простого оптического распознавания символов
Простой механизм OCR применяет множество различных хранимых шаблонов шрифтов и изображений текста в качестве шаблонов. Программное обеспечение OCR использует алгоритмы сопоставления шаблонов для посимвольного сравнения изображений текста с внутренней базой данных. Подход, при котором система сопоставляет текст слово за словом, называется оптическим распознаванием слов. Он имеет свои ограничения, поскольку существует практически неограниченное количество шрифтов и стилей почерка, и каждый отдельный тип не может быть учтен и сохранен в базе данных.
Он имеет свои ограничения, поскольку существует практически неограниченное количество шрифтов и стилей почерка, и каждый отдельный тип не может быть учтен и сохранен в базе данных.
Программы интеллектуального распознавания символов
Современные системы OCR используют технологию интеллектуального распознавания символов (ICR) для считывания текста так же, как это делает человек. Они используют передовые методы машинного обучения человеческим навыкам чтения. Система машинного обучения, называемая нейронной сетью, анализирует текст на многих уровнях, многократно обрабатывая изображение. Она ищет различные атрибуты изображения (кривые, линии, пересечения и петли) и объединяет результаты различных уровней анализа для получения окончательного результата. Несмотря на то, что ICR обрабатывает изображения по символам, процесс не занимает много времени, а результаты получаются за считанные секунды.
Интеллектуальное распознавание слов
Интеллектуальные системы распознавания слов работают по тому же принципу, что и ICR, но обрабатывают изображения целых слов без предварительного выделения символов в изображении.
Оптическое распознавание знаков
Оптическое распознавание знаков позволяет идентифицировать логотипы, водяные знаки и другие обозначения в документе.
В чем заключаются основные преимущества OCR?
Специалисты по анализу данных классифицируют различные виды технологий OCR на основе их использования и применения. Ниже представлены лишь некоторые примеры:
Программы простого оптического распознавания символов
Простой механизм OCR применяет множество различных хранимых шаблонов шрифтов и изображений текста в качестве шаблонов. Программное обеспечение OCR использует алгоритмы сопоставления шаблонов для посимвольного сравнения изображений текста с внутренней базой данных. Подход, при котором система сопоставляет текст слово за словом, называется оптическим распознаванием слов. Он имеет свои ограничения, поскольку существует практически неограниченное количество шрифтов и стилей почерка, и каждый отдельный тип не может быть учтен и сохранен в базе данных.
Программы интеллектуального распознавания символов
Современные системы OCR используют технологию интеллектуального распознавания символов (ICR) для считывания текста так же, как это делает человек. Они используют передовые методы машинного обучения человеческим навыкам чтения. Система машинного обучения, называемая нейронной сетью, анализирует текст на многих уровнях, многократно обрабатывая изображение. Она ищет различные атрибуты изображения (кривые, линии, пересечения и петли) и объединяет результаты различных уровней анализа для получения окончательного результата. Несмотря на то, что ICR обрабатывает изображения по символам, процесс не занимает много времени, а результаты получаются за считанные секунды.
Интеллектуальное распознавание слов
Интеллектуальные системы распознавания слов работают по тому же принципу, что и ICR, но обрабатывают изображения целых слов без предварительного выделения символов в изображении.
Оптическое распознавание знаков
Оптическое распознавание знаков позволяет идентифицировать логотипы, водяные знаки и другие обозначения в документе.
В чем заключаются основные преимущества OCR?
Ниже приведены основные преимущества технологии OCR:
Текст с возможностью поиска
Предприятия могут преобразовывать имеющиеся и новые документы в базу знаний с возможностью полноценного поиска. ПО для автоматической обработки текстовой базы позволяет совершенствовать базу знаний предприятия.
Эффективность работы
Применение ПО OCR позволяет повысить эффективность работы путем автоматической интеграции документооборота и цифровых рабочих процессов. Вот несколько примеров того, что может сделать ПО OCR:
- Сканирование заполненных вручную форм для автоматизированной проверки, рассмотрения, редактирования и анализа. Такой подход сокращает время ручной обработки документов и ввода данных.
- Поиск необходимых документов с помощью быстрого поиска термина в базе данных, вместо ручного перебора файлов в ящике.
- Преобразование рукописных заметок в редактируемые тексты и документы.

Решения искусственного интеллекта
OCR часто является составляющей других решений в области искусственного интеллекта, которые могут внедрять предприятия. К примеру, OCR может применяться для сканирования и распознавания номерных знаков и дорожных указателей в самоуправляемых автомобилях, выявления логотипов брендов в сообщениях в социальных сетях или идентификации упаковки продукта в рекламных изображениях. Такие технологии искусственного интеллекта помогают предприятиям принимать более эффективные маркетинговые и операционные решения, которые позволяют сократить расходы и улучшить качество обслуживания клиентов.
Для чего применяется OCR?
Ниже перечислены некоторые распространенные случаи использования OCR в различных отраслях:
Банковская сфера
Банковская сфера использует OCR для обработки и проверки документов по кредитам, депозитных чеков и других финансовых операций. Такая проверка позволила повысить эффективность борьбы с мошенничеством и укрепить безопасность транзакций. Например, BlueVine, финансовая технологическая компания, предоставляющая финансирование малому и среднему бизнесу, использовала Amazon Textract, облачный сервис OCR, для разработки продукта, с помощью которого малые бизнесы в США могут быстро получить доступ к кредитам по Программе защиты заработной платы (PPP) в рамках пакета мер по стимулированию экономики в условиях COVID-19. Amazon Textract автоматически обрабатывал и анализировал десятки тысяч форм PPP в день, благодаря чему BlueVine смогла помочь нескольким тысячам предприятий получить средства и сохранить более 400 000 рабочих мест.
Например, BlueVine, финансовая технологическая компания, предоставляющая финансирование малому и среднему бизнесу, использовала Amazon Textract, облачный сервис OCR, для разработки продукта, с помощью которого малые бизнесы в США могут быстро получить доступ к кредитам по Программе защиты заработной платы (PPP) в рамках пакета мер по стимулированию экономики в условиях COVID-19. Amazon Textract автоматически обрабатывал и анализировал десятки тысяч форм PPP в день, благодаря чему BlueVine смогла помочь нескольким тысячам предприятий получить средства и сохранить более 400 000 рабочих мест.
Здравоохранение
В системе здравоохранения OCR используется для обработки историй болезни пациентов, включая лечебные процедуры, анализы, больничные карты и страховые выплаты. OCR помогает оптимизировать рабочий процесс и сократить объем ручной работы в больницах, а также поддерживать актуальность записей. Например, компания nib Group обеспечивает медицинское страхование более 1 миллиона австралийцев и ежедневно получает тысячи заявок на выплату страхового возмещения за получение медицинских услуг. Клиенты компании могут сфотографировать свой медицинский счет и отправить его через мобильное приложение nib. Amazon Textract автоматически обрабатывает эти изображения, что позволяет компании гораздо быстрее рассматривать заявки.
Клиенты компании могут сфотографировать свой медицинский счет и отправить его через мобильное приложение nib. Amazon Textract автоматически обрабатывает эти изображения, что позволяет компании гораздо быстрее рассматривать заявки.
Логистика
Логистические компании используют OCR для более эффективного отслеживания этикеток на упаковках, счетов, квитанций и других документов. Например, компания Foresight Group использует Amazon Textract для автоматизации обработки счетов в SAP. Ввод таких документов вручную отнимал много времени и приводил к ошибкам, поскольку сотрудникам Foresight приходилось вводить данные в несколько систем бухгалтерского учета. Благодаря Amazon Textract программное обеспечение компании Foresight стало более точно считывать символы на различных носителях и повысило эффективность ведения бизнеса компании.
Как AWS может помочь с OCR?
AWS предлагает две услуги, которые могут помочь внедрить OCR в бизнесе:
Amazon Textract – это сервис машинного обучения (ML), который с помощью OCR автоматически извлекает печатный и рукописный текст и данные из отсканированных документов (например, PDF-файлов). Сервис позволяет быстро считывать тысячи различных документов различных носителей и форматов. После извлечения информации из документов Amazon Textract присваивает уровень уверенности, что дает возможность принимать обоснованные решения о том, как использовать полученные результаты.
Сервис позволяет быстро считывать тысячи различных документов различных носителей и форматов. После извлечения информации из документов Amazon Textract присваивает уровень уверенности, что дает возможность принимать обоснованные решения о том, как использовать полученные результаты.
Amazon Rekognition может анализировать миллионы изображений и видеозаписей за считанные минуты и дополнять задачи визуальной проверки, выполняемые человеком, с помощью искусственного интеллекта. Для извлечения текста из изображений и видео можно использовать API Amazon Rekognition. В нем имеется возможность распознавать искаженный и деформированный текст из изображений и видеозаписей дорожных знаков, публикаций в социальных сетях и упаковок продуктов.
Создайте учетную запись AWS и начните работу с технологией OCR уже сегодня.
Сканирование текстов и изображений
Во многих организациях хранятся тысячи и тысячи документов, созданных в докомпьютерную эпоху, и они все еще активно используются и периодически обновляются. Использование таких документов в их первозданном виде занимает много времени и средств. Кроме того, документы могут быть испорчены, перепутаны или потеряны.
Использование таких документов в их первозданном виде занимает много времени и средств. Кроме того, документы могут быть испорчены, перепутаны или потеряны.
Преобразование документов в электронный вид делает их «вечно живыми» и доступными широкому кругу прикладных программ. До недавнего времени такое преобразование было непростительно дорого, но, с разработкой современных технологий, процесс стал экономически оправдан. Условно сканирование можно разделить на две части: сканирование текста и изображений.
Оптическое и интерполированное разрешение
Оптическое разрешение — измеряется в точках на дюйм (dots per inch, dpi). Характеристика, показывающая, чем больше разрешение, тем больше информации об оригинале может быть введено в компьютер и подвергнуто дальнейшей обработке. Часто приводится такая характеристика, как «интерполированное (или «улучшенное») разрешение». Ценность этого показателя сомнительна — это условное разрешение, до которого программа сканера «берется досчитать» недостающие точки. Этот параметр не имеет никакого отношения к механизму сканера и, если интерполяция все же нужна, то делать это лучше после сканирования с помощью хорошего графического пакета.
Этот параметр не имеет никакого отношения к механизму сканера и, если интерполяция все же нужна, то делать это лучше после сканирования с помощью хорошего графического пакета.
Глубина цвета
Глубина цвета — это характеристика, обозначающая количество цветов, которое способен распознать сканер. Большинство компьютерных приложений, исключая профессиональные графические пакеты, такие как Photoshop, работают с 24 битным представлением цвета (полное количество цветов -16.77 млн. на точку). У сканеров эта характеристика, как правило, выше — 36 бит, и, у наиболее качественных из планшетных сканеров, — 34 бит и более. Конечно, может возникнуть вопрос — зачем сканеру распознавать больше бит, чем он может передать в компьютер. Однако, не все полученные биты равноценны.
В сканерах с ПЗС датчиками два верхних бита теоретической глубины цвета обычно являются «шумовыми» и не несут точной информации о цвете. Наиболее очевидное следствие «шумовых» битов недостаточно непрерывные, гладкие переходы между смежными градациями яркости в оцифрованных изображениях.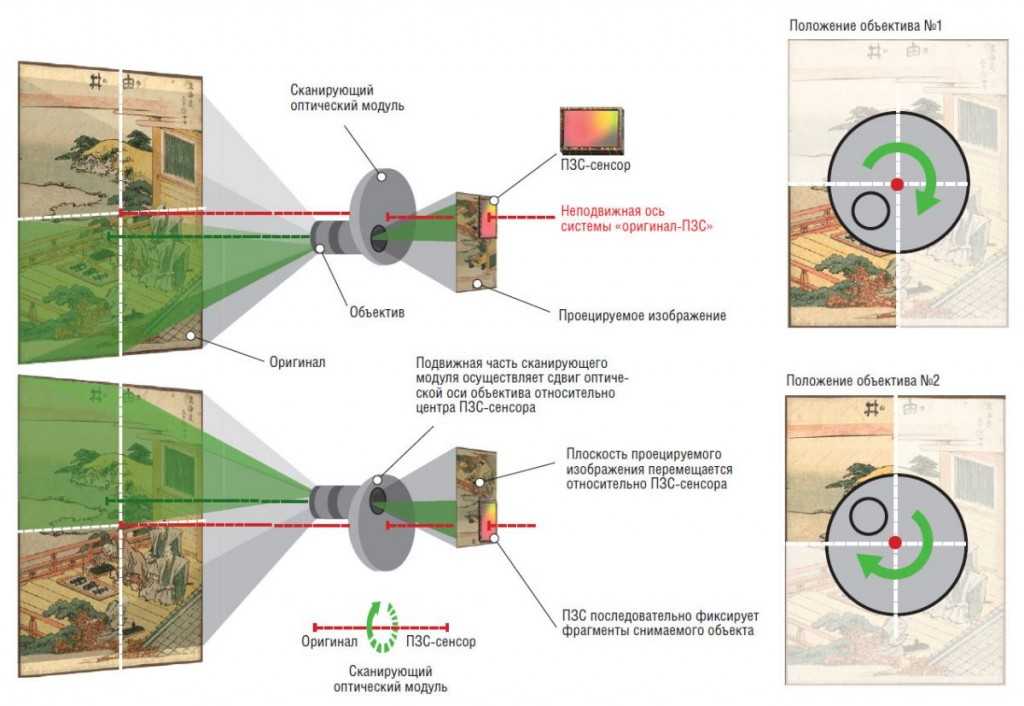 Соответственно в 42-битном сканере «шумовые» биты можно сдвинуть достаточно далеко, и в конечном оцифрованном изображении останется больше чистых тонов на канал цвета.
Соответственно в 42-битном сканере «шумовые» биты можно сдвинуть достаточно далеко, и в конечном оцифрованном изображении останется больше чистых тонов на канал цвета.
Динамический диапазон (диапазон оптических плотностей)
Оптическая плотность — это характеристика оригинала, равная десятичному логарифму отношения света падающего на оригинал, к свету отраженному (или прошедшему — для прозрачных оригиналов). Минимально возможное значение 0.0 D — идеально белый (прозрачный) оригинал. Значение 4.0 D — абсолютно черный (непрозрачный) оригинал.
Динамический диапазон сканера характеризует какой диапазон оптических плотностей оригинала сканер может распознать, не потеряв оттенки ни в светах, ни в тенях оригинала. Максимальная оптическая плотность у сканера — это оптическая плотность оригинала, которую сканер еще отличает от полной темноты. Все оттенки оригинала темнее этой границы сканер не сможет различить. Данная величина очень хорошо отделяет простые офисные сканеры, которые могут потерять детали, как в темных, так и светлых участках слайда и, тем более, негатива, от более профессиональных моделей. Как правило, для большинства планшетных сканеров данная величина лежит в пределах от 1.7D (офисные модели) до 3.4 D (полупрофессиональные модели).
Данная величина очень хорошо отделяет простые офисные сканеры, которые могут потерять детали, как в темных, так и светлых участках слайда и, тем более, негатива, от более профессиональных моделей. Как правило, для большинства планшетных сканеров данная величина лежит в пределах от 1.7D (офисные модели) до 3.4 D (полупрофессиональные модели).
Большинство бумажных оригиналов, будь то фотография или журнальная вырезка, обладают оптической плотностью не более 2.5D. Слайды требуют для качественного сканирования, как правило, динамический диапазон более 2.7 D (Обычно 3.0 — 3.8). И только негативы и рентгеновские снимки обладают более высокими плотностями (3.3D — 4.0D), и покупать сканер с большим динамическим диапазоном имеет смысл, если вы будете работать в основном с ними, иначе вы просто переплатите деньги.
Программное обеспечение и другие характеристики
При выборе сканера следует учитывать и некоторые другие параметры, например, возможность сканирования с прозрачных и непрозрачных оригиналов, возможность пакетного сканирования и распознавания. Важным моментом является программное обеспечение, прилагаемое к сканерам. Особое внимание следует уделить соответствию выбранного вами программного обеспечения тем задачам, которые вам придется решать с помощью сканера. Для рекламной деятельности необходима мощная программа с возможностями ручных настроек и с возможностью цветокалибрации сканера, а для сканирования текстов необходимо обратить внимание на совместимость с программой распознавания, что, как правило, обеспечивается соответствием драйвера сканера стандарту Twain.
Важным моментом является программное обеспечение, прилагаемое к сканерам. Особое внимание следует уделить соответствию выбранного вами программного обеспечения тем задачам, которые вам придется решать с помощью сканера. Для рекламной деятельности необходима мощная программа с возможностями ручных настроек и с возможностью цветокалибрации сканера, а для сканирования текстов необходимо обратить внимание на совместимость с программой распознавания, что, как правило, обеспечивается соответствием драйвера сканера стандарту Twain.
Получайте новости с schooldesk на почту
Оптическое сканирование Определение и значение
- Основные определения
- Викторина
- Сопутствующее содержимое
- Примеры
Показывает уровень оценки в зависимости от сложности слова.
[ оп-ти-куль сканирование ]
/ ˈɒp tɪ kəl ˈskæn ɪŋ /
Сохранить это слово!
См. синонимы оптического сканирования на сайте Thesaurus.com
синонимы оптического сканирования на сайте Thesaurus.com
Показывает уровень оценки в зависимости от сложности слова.
существительное
процесс интерпретации данных в печатной, рукописной, штриховой или другой визуальной форме с помощью оптического сканера.
ВИКТОРИНА
ВЫ ПРОЙДЕТЕ ЭТИ ГРАММАТИЧЕСКИЕ ВОПРОСЫ ИЛИ НАТЯНУТСЯ?
Плавно переходите к этим распространенным грамматическим ошибкам, которые ставят многих людей в тупик. Удачи!
Вопрос 1 из 7
Заполните пропуск: Я не могу понять, что _____ подарил мне этот подарок.
Сравните оптическое распознавание символов.
Происхождение оптического сканирования
Впервые записано в 1955–60 гг.
Слова рядом с оптическим сканированием
оптическая накачка, оптический пирометр, оптический резонатор, оптическое вращение, оптический сканер, оптическое сканирование, оптический звук, оптический саундтрек, оптический инструмент, оптический пинцет, оптический клин
Dictionary. com без сокращений
com без сокращений
На основе Random House Unabridged Dictionary, © Random House, Inc. 2022
Слова, относящиеся к оптическому сканированию
сканер
Как использовать оптическое сканирование в предложении
После сканирования KSM ведут по длинному коридору, обрамленному сетчатыми заборами.
9/11 Mastermind Is Afraid of the Ladies|Тим Мак|16 декабря 2014 г.|DAILY BEAST
Его 8-мегапиксельная камера, включающая вспышку True-Tone и двойную светодиодную вспышку с диафрагмой f/2.2, поддерживает оптическое изображение стабилизация.
Почему в этот праздник каждому дому нужен дрон|Чарли Гилберт|8 декабря 2014|DAILY BEAST
Но однажды, просматривая объявления в Minneapolis Tribune, она увидела вакансию, которая ей понравилась.
Гей-сказка о доме Чарли Мэнсона на полигоне|Гей-сказка|31 октября 2014 г.|DAILY BEAST
Даже если вы пропустите математику, просто просмотрите его список следствий.

Как определить, что научное исследование является полной чушью|Рассел Сондерс|22 августа 2014 г.|DAILY BEAST
Сканирование системы безопасности в Куала-Лумпуре ничего не зафиксировало.
Рейс 370 перевозил 440 фунтов опасных батарей | Клайв Ирвинг | 1 мая 2014 г. | DAILY BEAST
Банда партизан увидела их, остановилась и внимательно их осматривала, как будто решая, наступать или нет.
Курьер Озарков|Байрон А. Данн
Жаркая атмосфера, неподвижный воздух, несомненно, создавали оптическую иллюзию.
Волна|Алджернон Блэквуд
Автоматически взяв карандаш, он внимательно просматривал кроссворд.
Детектив в капюшоне, Том III № 2, 19 января42|Разное
Будучи еще молодым человеком, которому только что исполнилось сорок, он один из выдающихся людей своего времени.
Состояние, возвышение, эмиграция и судьба цветного населения Соединенных Штатов|Мартин Р.
 Делани
ДеланиОна была одержима идеей, что в тот день в Сан-Франциско был только один человек, несмотря ни на что. оптический обман.
Предки|Гертруда Атертон
Использование оптического сканирования как средства компьютерного ввода в медицине | ДЖАМА
Использование оптического сканирования как средства компьютерного ввода в медицине | ДЖАМА | Сеть ДЖАМА
[Перейти к навигации]
Эта проблема
- Скачать PDF
- Полный текст
Поделиться
Твиттер
Фейсбук
Эл. адрес
LinkedIn- Процитировать это
- Разрешения
Артикул
28 апреля 1969 г.
Брюс Э. Спайви, MD ; Джон О’Нил
Принадлежности автора
Отделение офтальмологии Медицинского колледжа Университета Айовы, Айова-Сити, Айова.
ДЖАМА. 1969; 208(4):665-672. дои: 10.1001/jama.1969.03160040073011
Полный текст
Абстрактный
Использование компьютеров в медицине в настоящее время широко распространено и принято. Основной проблемой при использовании компьютера является ввод. Оптическое сканирование представлено как механизм компьютерного ввода. В качестве примеров используются три практических приложения оптического сканирования: запись (1) диагноза пациента, (2) лабораторных данных и (3) результатов комплексного офтальмологического обследования. При правильном использовании оптическое сканирование обеспечивает эффективное и действенное средство, помогающее процессу ввода для возможного поиска информации и анализа данных в медицине.
Всего комментариев: 0