Сгенерирована как пишется: Как правильно пишется слово Сгенерировать. Синонимы слова Сгенерировать
Содержание
Файл .gitignore — игнорирование файлов в Git
Git рассматривает каждый файл в вашей рабочей копии как файл одного из трех нижеуказанных типов.
- Отслеживаемый файл — файл, который был предварительно проиндексирован или зафиксирован в коммите.
- Неотслеживаемый файл — файл, который не был проиндексирован или зафиксирован в коммите.
- Игнорируемый файл — файл, явным образом помеченный для Git как файл, который необходимо игнорировать.
Игнорируемые файлы — это, как правило, артефакты сборки и файлы, генерируемые машиной из исходных файлов в вашем репозитории, либо файлы, которые по какой-либо иной причине не должны попадать в коммиты. Вот некоторые распространенные примеры таких файлов:
- кэши зависимостей, например содержимое
/node_modulesили/packages; - скомпилированный код, например файлы
.o,.pycи.class; - каталоги для выходных данных сборки, например
/bin,/outили/target; - файлы, сгенерированные во время выполнения, например
., log
log.lockили.tmp; - скрытые системные файлы, например
.DS_StoreилиThumbs.db; - личные файлы конфигурации IDE, например
.idea/workspace.xml.
 log
logИгнорируемые файлы отслеживаются в специальном файле .gitignore, который регистрируется в корневом каталоге репозитория. В Git нет специальной команды для указания игнорируемых файлов: вместо этого необходимо вручную отредактировать файл .gitignore, чтобы указать в нем новые файлы, которые должны быть проигнорированы. Файлы .gitignore содержат шаблоны, которые сопоставляются с именами файлов в репозитории для определения необходимости игнорировать эти файлы.
- Игнорирование файлов в Git
- Шаблоны игнорирования в Git
- Общие файлы .gitignore в вашем репозитории
- Персональные правила игнорирования в Git
- Глобальные правила игнорирования в Git
- Игнорирование ранее закоммиченного файла
- Коммит игнорируемого файла
- Скрытие изменений в игнорируем файле
- Отладка файлов .
 gitignore
gitignore
Шаблоны игнорирования в Git
Для сопоставления с именами файлов в .gitignore используются шаблоны подстановки. С помощью различных символов можно создавать собственные шаблоны.
| Шаблон | Примеры соответствия | Пояснение* |
|---|---|---|
**/logs | logs/debug.loglogs/monday/foo.barbuild/logs/debug.log | Добавьте в начало шаблона две звездочки, чтобы сопоставлять каталоги в любом месте репозитория. |
**/logs/debug.log | logs/debug.logbuild/logs/debug.logно не logs/build/debug.log | Две звездочки можно также использовать для сопоставления файлов на основе их имени и имени родительского каталога. |
*.log | debug.logfoo.log.logs/debug.log | Одна звездочка — это подстановочный знак, который может соответствовать как нескольким символам, так и ни одному. |
*.log !important.log | debug.logtrace.logно не important.loglogs/important.log | Добавление восклицательного знака в начало шаблона отменяет действие шаблона. Если файл соответствует некоему шаблону, но при этом также соответствует отменяющему шаблону, указанному после, такой файл не будет игнорироваться. |
*.log !important/*.logtrace.* | debug.logimportant/trace.logно не important/debug.log | Шаблоны, указанные после отменяющего шаблона, снова будут помечать файлы как игнорируемые, даже если ранее игнорирование этих файлов было отменено. |
/debug.log | debug.logно не logs/debug.log | Косая черта перед именем файла соответствует файлу в корневом каталоге репозитория. |
debug.log | debug.loglogs/debug.log | По умолчанию шаблоны соответствуют файлам, находящимся в любом каталоге |
debug?.log | debug0.logdebugg.logно не debug10.log | Знак вопроса соответствует строго одному символу. |
debug[0-9].log | debug0.logdebug1.logно не debug10.log | Квадратные скобки можно также использовать для указания соответствия одному символу из заданного диапазона. |
debug[01].log | debug0.logdebug1.но не debug2.logdebug01.log | Квадратные скобки соответствуют одному символу из указанного набора. |
debug[!01].log | debug2.logно не debug0.logdebug1.logdebug01.log | Восклицательный знак можно использовать для указания соответствия любому символу, кроме символов из указанного набора. |
debug[a-z].log | debuga.logdebugb.logно не debug1.log | Диапазоны могут быть цифровыми или буквенными. |
logs | logslogs/debug.loglogs/latest/foo.barbuild/logsbuild/logs/debug.log | Без косой черты в конце этот шаблон будет соответствовать и файлам, и содержимому каталогов с таким именем. В примере соответствия слева игнорируются и каталоги, и файлы с именем logs В примере соответствия слева игнорируются и каталоги, и файлы с именем logs |
| logs/ | logs/debug.loglogs/latest/foo.barbuild/logs/foo.barbuild/logs/latest/debug.log | Косая черта в конце шаблона означает каталог. Все содержимое любого каталога репозитория, соответствующего этому имени (включая все его файлы и подкаталоги), будет игнорироваться |
logs/ !logs/important.log | logs/debug.loglogs/important.log | Минуточку! Разве файл logs/important.log из примера слева не должен быть исключен нз списка игнорируемых?Нет! Из-за странностей Git, связанных с производительностью, вы не можете отменить игнорирование файла, которое задано шаблоном соответствия каталогу |
logs/**/debug.log | logs/debug.loglogs/monday/debug.logs/monday/pm/debug.log | Две звездочки соответствуют множеству каталогов или ни одному. |
logs/*day/debug.log | logs/monday/debug.loglogs/tuesday/debug.logbut not logs/latest/debug.log | Подстановочные символы можно использовать и в именах каталогов. |
logs/debug.log | logs/debug.logно не debug.logbuild/logs/debug.log | Шаблоны, указывающие на файл в определенном каталоге, задаются относительно корневого каталога репозитория. (При желании можно добавить в начало косую черту, но она ни на что особо не повлияет.) |
 log
log log
log log
logДве звездочки (**) означают, что ваш файл .gitignore находится в каталоге верхнего уровня вашего репозитория, как указано в соглашении. Если в репозитории несколько файлов .gitignore, просто мысленно поменяйте слова «корень репозитория» на «каталог, содержащий файл . gitignore» (и подумайте об объединении этих файлов, чтобы упростить работу для своей команды)*.
gitignore» (и подумайте об объединении этих файлов, чтобы упростить работу для своей команды)*.
Помимо указанных символов, можно использовать символ #, чтобы добавить в файл .gitignore комментарии:
# ignore all logs
*.log
Если у вас есть файлы или каталоги, в имени которых содержатся спецсимволы шаблонов, для экранирования этих спецсимволов в .gitignore можно использовать обратную косую черту (\):
# ignore the file literally named foo[01].txt
foo\[01\].txt
Общие файлы .gitignore в вашем репозитории
Обычно правила игнорирования Git задаются в файле .gitignore в корневом каталоге репозитория. Тем не менее вы можете определить несколько файлов .gitignore в разных каталогах репозитория. Каждый шаблон из конкретного файла .gitignore проверяется относительно каталога, в котором содержится этот файл. Однако проще всего (и этот подход рекомендуется в качестве общего соглашения) определить один файл . в корневом каталоге. После регистрации файла  gitignore
gitignore.gitignore для него, как и для любого другого файла в репозитории, включается контроль версий, а после публикации с помощью команды push он становится доступен остальным участникам команды. В файл .gitignore, как правило, включаются только те шаблоны, которые будут полезны другим пользователям репозитория.
Персональные правила игнорирования в Git
В специальном файле, который находится в папке .git/info/exclude, можно определить персональные шаблоны игнорирования для конкретного репозитория. Этот файл не имеет контроля версий и не распространяется вместе с репозиторием, поэтому он хорошо подходит для указания шаблонов, которые будут полезны только вам. Например, если у вас есть пользовательские настройки для ведения журналов или специальные инструменты разработки, которые создают файлы в рабочем каталоге вашего репозитория, вы можете добавить их в .git/info/exclude, чтобы они случайно не попали в коммит в вашем репозитории.
Глобальные правила игнорирования в Git
Кроме того, для всех репозиториев в локальной системе можно определить глобальные шаблоны игнорирования Git, настроив параметр конфигурации Git core.excludesFile . Этот файл нужно создать самостоятельно. Если вы не знаете, куда поместить глобальный файл .gitignore, расположите его в домашнем каталоге (потом его будет легче найти). После создания этого файла необходимо настроить его местоположение с помощью команды git config:
$ touch ~/.gitignore
$ git config --global core.excludesFile ~/.gitignore
Будьте внимательны при указании глобальных шаблонов игнорирования, поскольку для разных проектов актуальны различные типы файлов. Типичные кандидаты на глобальное игнорирование — это специальные файлы операционной системы (например, .DS_Store и thumbs.db) или временные файлы, создаваемые некоторыми инструментами разработки.
Игнорирование ранее закоммиченного файла
Чтобы игнорировать файл, для которого ранее был сделан коммит, необходимо удалить этот файл из репозитория, а затем добавить для него правило в . . Используйте команду  gitignore
gitignoregit rm с параметром --cached, чтобы удалить этот файл из репозитория, но оставить его в рабочем каталоге как игнорируемый файл.
$ echo debug.log >> .gitignore
$ git rm --cached debug.log
rm 'debug.log'
$ git commit -m "Start ignoring debug.log"
Опустите опцию --cached, чтобы удалить файл как из репозитория, так и из локальной файловой системы.
Коммит игнорируемого файла
Можно принудительно сделать коммит игнорируемого файла в репозиторий с помощью команды git add с параметром -f (или --force):
$ cat .gitignore
*.log
$ git add -f debug.log
$ git commit -m "Force adding debug.log"
Этот способ хорош, если у вас задан общий шаблон (например, *.log), но вы хотите сделать коммит определенного файла. Однако еще лучше в этом случае задать исключение из общего правила:
$ echo !debug.log >> .gitignore
$ cat .gitignore
*.log
!debug.log
$ git add debug.log
$ git commit -m "Adding debug.log"
Этот подход более прозрачен и понятен, если вы работаете в команде.
Скрытие изменений в игнорируем файле
Команда git stash — это мощная функция системы Git, позволяющая временно отложить и отменить локальные изменения, а позже применить их повторно. По умолчанию команда git stash ожидаемо не обрабатывает игнорируемые файлы и создает отложенные изменения только для тех файлов, которые отслеживаются Git. Тем не менее вы можете вызвать команду git stash с параметром —all, чтобы создать отложенные изменения также для игнорируемых и неотслеживаемых файлов.
Отладка файлов .gitignore
Если шаблоны .gitignore сложны или разбиты на множество файлов .gitignore, бывает непросто отследить, почему игнорируется определенный файл. Используйте команду git check-ignore с параметром -v (или --verbose), чтобы определить, какой шаблон приводит к игнорированию конкретного файла:
$ git check-ignore -v debug.log
.gitignore:3:*.log debug.log
Вывод показывает:
<file containing the pattern> : <line number of the pattern> : <pattern> <file name>
При желании команде git check-ignore можно передать несколько имен файлов, причем сами имена могут даже не соответствовать файлам, существующим в вашем репозитории.
Как правильно писать логи (?) / Хабр
Тема может и банальная, но когда программа начинает работать как то не так, и вообще вести себя очень странно, часто приходится читать логи. И много логов, особенно если нет возможности отлаживать программу и не получается воспроизвести ошибку. Наверно каждый выработал для себя какие то правила, что, как и когда логировать. Ниже я хочу рассмотреть несколько правил записи сообщений в лог, а также будет небольшое сравнение библиотек логирования для языков php, ruby и go. Сборщики логов и системы доставки не будут рассматриваться сознательно (их обсуждали уже много раз).
Есть такая linux утилита, а также по совместительству сетевой протокол под названием syslog. И есть целый набор RFC посвящённый syslog, один из них описывает уровни логирования https://en.wikipedia.org/wiki/Syslog#Severity_level (https://tools.ietf.org/html/rfc5424). Согласно rfc 5424 для syslog определено 8 уровней логирования, для которых также дается краткое описание. Данные уровни логирования были переняты многими популярными логерами для разных языков программирования. Например, http://www.php-fig.org/psr/psr-3/ определяет те же самые 8 уровней логирования, а стандартный Ruby logger использует немного сокращённый набор из 5 уровней. Несмотря на формальное указание в каких случаях должен быть использован тот или иной уровень логов, зачастую используется комбинация вроде debug/info/fatal — первый для логирования во время разработки и тестирования, второй и третий в расчёте на продакшен. Потом в какой то момент на продакшене начинает происходить что то не понятное и вдруг оказывается, что info логов не хватает — бежим включать debug. И если они не сильно нагружают систему, то зачастую так и остаются включенными в продакшен окружении. По факту остаётся два сценария, когда нужно иметь логи:
И если они не сильно нагружают систему, то зачастую так и остаются включенными в продакшен окружении. По факту остаётся два сценария, когда нужно иметь логи:
- что-то происходит и надо знать что
- что-то сломалось и нужно дополнительно активировать триггер
По триггеру может происходить: уведомление об ошибке на email, аварийное завершение или перезапуск программы или другие типичные сценарии.
В языке Go в котором всё упрощено до предела, стандартный логер тоже прилично покромсали и оставили следующие варианты:
- Fatal — вывод в лог и немедленный выход в ОС.
- Panic — вывод в лог и возбуждение «паники» (аналог исключения)
- Print — просто выводит сообщение в лог
Запутаться, что использовать в конкретной ситуации уже практически невозможно. Но сообщения в таком сильно усеченном виде сложно анализировать, а также настраивать системы оповещения, типично реагирующих на какой нибудь Alert\Fatal\Error в тексте лога.
Я часто при написании программы с нуля повсеместно использую debug уровень для логирования с расчётом, что на продакшене будет выставлен уровень логирования info и тем самым сократится зашумлённость сообщениями. Но в таком подходе часто возникают ситуация, что логов вдруг становится не хватать. Трудно угадать, какая информация понадобиться, что бы отловить редкий баг. Возможно рационально всегда использовать по умолчанию уровень info, а в обработчиках ошибок уровень error и выше. Но если у вас сотни и больше сообщений лога в секунду, то тогда наверно есть смысл тонкой настройки между info/debug. В таких ситуациях уже имеет смысл использовать специализированные решения что бы не просаживать производительность.
Есть ещё тонкий момент, когда вы пишите что то вроде logger.debug(entity.values) — то при выставленном уровне логирования выше debug содержимое entity.values не попадёт в лог, но оно каждый раз будет вычисляться отъедая ресурсы. В Ruby логеру можно передать вместо строки сообщения блок кода: Logger.. В таком случае вычисления будут происходить только при выставленном соответствующем уровне лога. В языке Go для реализации ленивого вычисления в логер можно передать объект поддерживающий интерфейс Stringer. debug { entity.values }
debug { entity.values }
После того, как разобрались с использованием уровней логов, нужно ещё уметь связывать разрозненные сообщения, особенно это актуально для многопоточных приложений или связанных между собой отдельных сервисов, когда в логах все сообщения оказываются вперемешку.
Типичный формат строки сообщения в логе можно условно разделить на следующие составные части:
[system info] + [message] + [context]
Где:
system info: метка времени, ид процесса, ид потока и другая служебная информацияmessage: текст сообщенияcontext: любая дополнительная информация, контекст может быть общим для сообщений в рамках какой то операции.
Для того, чтобы связать пары запрос\ответ часто используется http заголовок X-Request-ID. Такой заголовок может сгенерировать клиент, или он может быть сгенерирован на стороне сервера. Добавив его в контекст каждой строчки лога появится возможность лёгким движением руки найти все сообщения возникшие в рамках выполнения конкретного запроса. А в случае распределенных систем, заголовок можно передавать дальше по цепочке сетевых вызовов.
Такой заголовок может сгенерировать клиент, или он может быть сгенерирован на стороне сервера. Добавив его в контекст каждой строчки лога появится возможность лёгким движением руки найти все сообщения возникшие в рамках выполнения конкретного запроса. А в случае распределенных систем, заголовок можно передавать дальше по цепочке сетевых вызовов.
Но с единым контекстом в рамках запроса возникает проблема с различными ORM, http клиентами или другими сервисами\библиотеками, которые живут своей жизнью. И ещё хорошо, если они предоставляют возможность переопределить свой стандартный логер хотя бы глобально, а вот выставить контекст для логера в рамках запроса зачастую не реально. Данная проблема в основном актуальна для многопоточной обработки, когда один процесс обслуживает множество запросов. Но например в фрэймворке Rails имеется очень тесная интеграция между всеми компонентами и запросы ActiveRecord могут писаться в лог вместе с глобальным контекстом для текущего сетевого запроса. А в языке Go некоторые библиотеки логирования позволяют динамически создавать новый объект логера с нужным контекстом, выглядит это примерно так:
А в языке Go некоторые библиотеки логирования позволяют динамически создавать новый объект логера с нужным контекстом, выглядит это примерно так:
reqLog := log.WithField("requestID", requestID)
После этого такой экземпляр логера можно передать как зависимость в другие объекты. Но отсутствие стандартизированного интерфейса логирования (например как psr-3 в php) провоцирует создателей библиотек хардкодить малосовместимые реализации логеров. Поэтому если вы пишите свою библиотеку на Go и в ней есть компонент логирования, не забудьте предусмотреть интерфейс для замены логера на пользовательский.
Резюмируя:
- Логируйте с избытком. Никогда заранее не известно сколько и какой информации в логах понадобится в критический момент.
- Восемь уровней логирования — вам действительно столько надо? По опыту должно хватить максимум 3-4, и то при условии, что для них настроены обработчики событий.
- По возможности используйте ленивые вычисления для вывод сообщений в лог
- Всегда добавляйте текущий контекст в каждое сообщение лога, как минимум requestID.
- По возможности настраивайте сторонние библиотеки таким образом, чтобы они использовали логер с текущим контекстом запроса.
Google заявляет, что контент, сгенерированный искусственным интеллектом, противоречит руководящим принципам
Адвокат Google по вопросам поиска Джон Мюллер заявляет, что контент, автоматически созданный с помощью инструментов для письма с искусственным интеллектом, считается спамом в соответствии с рекомендациями поисковой системы для веб-мастеров.
Эта тема обсуждалась во время недавней встречи Google Search Central SEO в рабочие часы в ответ на вопрос об инструментах для письма GPT-3 AI.
В SEO-сообществе ведутся споры об использовании инструментов GPT-3 и о том, приемлемы ли они с точки зрения Google.
Мюллер говорит, что контент, написанный ИИ, подпадает под категорию автоматически сгенерированного контента, что может привести к ручному наказанию.
Однако системам Google может не хватать возможности обнаруживать контент, созданный ИИ, без помощи рецензентов.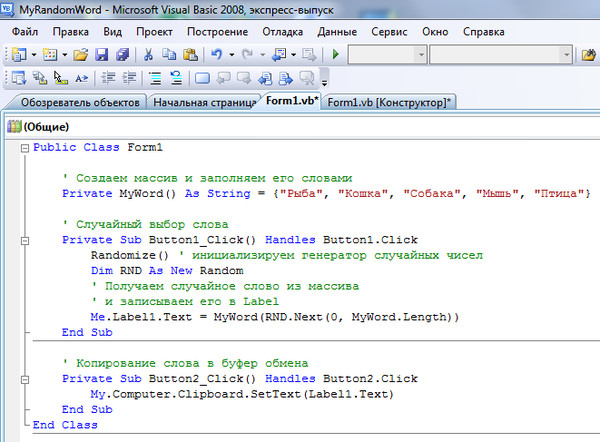
Как мы объясним далее в этой статье, у инструментов для письма с искусственным интеллектом есть практическое применение, и многие авторитетные организации используют их без проблем.
Во-первых, давайте посмотрим на ответ Мюллера на вопрос о том, как Google относится к использованию этих инструментов.
Автоматически создаваемый контент противоречит рекомендациям Google для веб-мастеров
Независимо от инструментов, используемых для его создания, контент, написанный машинами, считается автоматически созданным.
Как быстро отмечает Мюллер, позиция Google в отношении автоматически генерируемого контента всегда была ясной:
«Для нас они, по сути, по-прежнему попадали бы в категорию автоматически генерируемого контента, который мы имели в Рекомендации для веб-мастеров почти с самого начала.
И люди автоматически генерируют контент множеством различных способов. И для нас, если вы используете инструменты машинного обучения для создания своего контента, это, по сути, то же самое, как если бы вы просто перетасовывали слова, или искали синонимы, или выполняли приемы перевода, которые раньше делали люди.
Такие вещи.
Я подозреваю, что, возможно, качество контента немного лучше, чем у действительно старых инструментов, но для нас это по-прежнему автоматически генерируемый контент, а это значит, что для нас он по-прежнему противоречит Руководству для веб-мастеров. Поэтому мы будем считать это спамом».
Может ли Google обнаруживать контент, созданный ИИ?
Дополнительный вопрос касается способности Google идентифицировать контент, написанный с помощью инструментов машинного обучения.
Может ли Google понять разницу между контентом, написанным людьми, и контентом, написанным машинами?
Мюллер не заявляет, что Google автоматически обнаруживает написанный ИИ контент.
Хотя, если команда Google по борьбе с веб-спамом обнаружит его, они уполномочены принять меры по этому поводу.
«Я не могу этого утверждать. Но для нас, если мы видим, что что-то генерируется автоматически, тогда команда веб-спама определенно может принять меры по этому поводу.
И я не знаю, как там будет развиваться будущее, но я думаю, как и в случае с любой другой из этих технологий, будет немного игры в кошки-мышки, где иногда люди делают что-то, и им это сходит с рук , а затем группа по борьбе со спамом догоняет и решает эту проблему в более широком масштабе.
Из нашей рекомендации мы по-прежнему считаем это автоматически сгенерированным контентом. Я думаю, что со временем, возможно, это станет чем-то, что станет больше инструментом для людей. Это похоже на то, как если бы вы использовали машинный перевод в качестве основы для создания переведенной версии веб-сайта, но вы все еще работаете с ним вручную.
И, возможно, со временем эти инструменты ИИ будут развиваться в том направлении, в котором вы будете использовать их, чтобы быть более эффективными в своем письме или убедиться, что вы пишете правильно, как инструменты проверки орфографии и грамматики, которые также основаны по машинному обучению. Но я не знаю, что принесет туда будущее».


Мюллер поясняет, что Google не принимает во внимание то, как используются инструменты для письма ИИ.
Использование их в любом качестве считается спамом, добавляет он.
«В настоящее время это противоречит правилам для веб-мастеров. Поэтому, с нашей точки зрения, если бы мы столкнулись с чем-то подобным, если бы группа веб-спама увидела это, они бы восприняли это как спам».
Чтобы услышать его полный ответ, посмотрите видео ниже:
Что это значит для вашего сайта?
Вот некоторые мысли главы редакционной группы SEJ о том, что ответ Мюллера означает для вашего веб-сайта.
«Я думаю, что самый важный вывод из этого конкретного вопроса и ответа заключается в том, что алгоритмы Google не могут автоматически обнаруживать контент, созданный языковыми моделями, такими как GPT-3», — говорит 9.0066 Миранда Миллер, старший управляющий редактор здесь, в Search Engine Journal.
«Здесь сообщение состоит в том, что если Google обнаружит автоматически сгенерированный контент, команда по борьбе со спамом может принять меры. Но мы не говорим о прядильщиках статей 2003 года».
Но мы не говорим о прядильщиках статей 2003 года».
«Искусственный интеллект используется средствами массовой информации, университетами и другими организациями для автоматизации исследований и создания перекрестных ссылок, сканирования и классификации контента на многих языках для выявления новых тенденций, создания обзоров статей и статей, проверки фактов, обработки данных и даже писать полные статьи», — отмечает она.
«Ассошиэйтед Пресс начало использовать ИИ для создания материалов в 2014 году. Применение ИИ для создания контента не ново, и наиболее важным фактором здесь является его интеллектуальное применение», — говорит Миллер, отмечая, что использование ИИ может помочь создателям контента языковые и грамотные барьеры, улучшить качество своего письма и многое другое.
«Это хорошие результаты. Не было бы странно, если бы Google запретил использование ИИ веб-мастерами и создателями контента в целях улучшения пользовательского опыта, когда они сами так активно его используют?» — добавляет она.
Рекомендуемое изображение: Zapp2Photo/Shutterstock
Категория
Новости
SEO
Созданный компьютером текст, который выглядит реальным; настоящее письмо, которое выглядит сгенерированным компьютером
Вы знаете, когда вы смотрите на слово достаточно долго, оно начинает выглядеть странно? Буквы начинают отделяться друг от друга, и вы гиперосознаете произвольность связывания понятия с каким-то определенным сочетанием звуков? Для этого должно быть слово.
Во всяком случае, я вспомнил об этой диссоциации или сверхъестественной долине после прочтения отрывка из статьи Джона Сибрука о компьютерных программах, которые могут писать текст: что-то вроде автозаполнения в вашем телефоне, но вместо того, чтобы просто предлагать одно слово или фразу в раз, он будет писать целые предложения или абзацы.
Статью интересно читать, и у меня есть кое-какие дополнительные мысли по поводу статистического рабочего процесса, но сейчас я просто хотел указать на этот отрывок, рассказывающий о том, как Сибрук нажал кнопку, чтобы обучить бота для изучения языка на некоторых работах лингвист Стивен Пинкер, а затем попросил бота завершить электронное письмо, которое начал Пинкер. Вот Сибрук:
Вот Сибрук:
Я [Сибрук] поместил часть его ответа в окно генератора, щелкнул мандалу, добавил синтетическую прозу Пинкера к реальной вещи и попросил людей угадать, где остановился автор «Языкового инстинкта» и машина взяла верх.
Имея амнезию в отношении того, как он начал фразу или предложение, он не будет последовательно завершать его с необходимым согласием и согласием, не говоря уже о семантической связности. И это обнажает вторую проблему: настоящий язык не состоит из непрерывного монолога, который звучит как английский. Это способ выражения идей, преобразование смысла в звук или текст. Грубо говоря, речь или письмо — это коробка, входом которой является значение плюс коммуникативное намерение, а выходом — последовательность слов; понимание представляет собой коробку с обратным информационным потоком. Что существенно неверно в этой точке зрения, так это то, что она предполагает, что значение и намерение неразрывно связаны. Их разделение, как утверждает ученый Фил Цукерман, является иллюзией, которую мы встроили в свой мозг, ложным чувством согласованности.

Вы можете щелкнуть, чтобы узнать, где в этом проходе заканчивался человек и начинался компьютер. Что мне интересно, так это то, что при чтении абзаца с расчетом на то, что некоторые его части были сгенерированы компьютером, все выглядели сгенерированными компьютером! С самого начала: «Будучи амнезией того, как он начал фразу или предложение, он не будет постоянно завершать его необходимым соглашением…»: это выглядит как словесный салат — или, я думаю, уже должен сказать, фразовый салат.
Это как в «Бегущем по лезвию»: как только вы поймете, что ваш друг может быть репликантом, вы просто начнете смотреть на него по-другому. Существование стохастических алгоритмов письма позволяет нам осознать стохастическую алгоритмичность того, что мы читаем и пишем. Это заставляет нас задуматься об алгоритмах, которые каждый из нас использует для выражения своих мыслей.
Это не должно быть для меня новостью. Уже был случай, когда мой собственный писательский опыт сделал меня более осведомленным как читатель — я могу видеть швы там, где письмо было собрано воедино, — и тем более, когда мы думаем об алгоритмах.
P.S. Время от времени я критиковал Пинкера в этом блоге, поэтому позвольте мне пояснить, что (а) пример Сибрука с завершением абзаца Пинкера забавен, и (б) я почти уверен, что то же самое произошло бы, если бы кто-то должны были запустить один из моих абзацев через машинное обучение.
Во-первых, мое письмо (как и у Пинкера) шаблонно: у меня есть стиль, и есть вещи, о которых я люблю писать. Поэтому неудивительно, что можно написать что-то похожее на то, что пишу я, — по крайней мере, на короткие отрезки.
Во-вторых, если вы посмотрите на любое предложение, которое я пишу, оно начнет разваливаться. Каждое предложение работает как часть большой истории. Попытка найти слишком много смысла в каком-то одном предложении подобна разглядыванию одного мазка на картине. В конечном счете, это просто набор слов или какая-то краска, и он не может долго жить после того, как его сорвали с контекстуального дерева.
ОК, последнее я сделал намеренно, отвлекся и написал несколько бессвязно.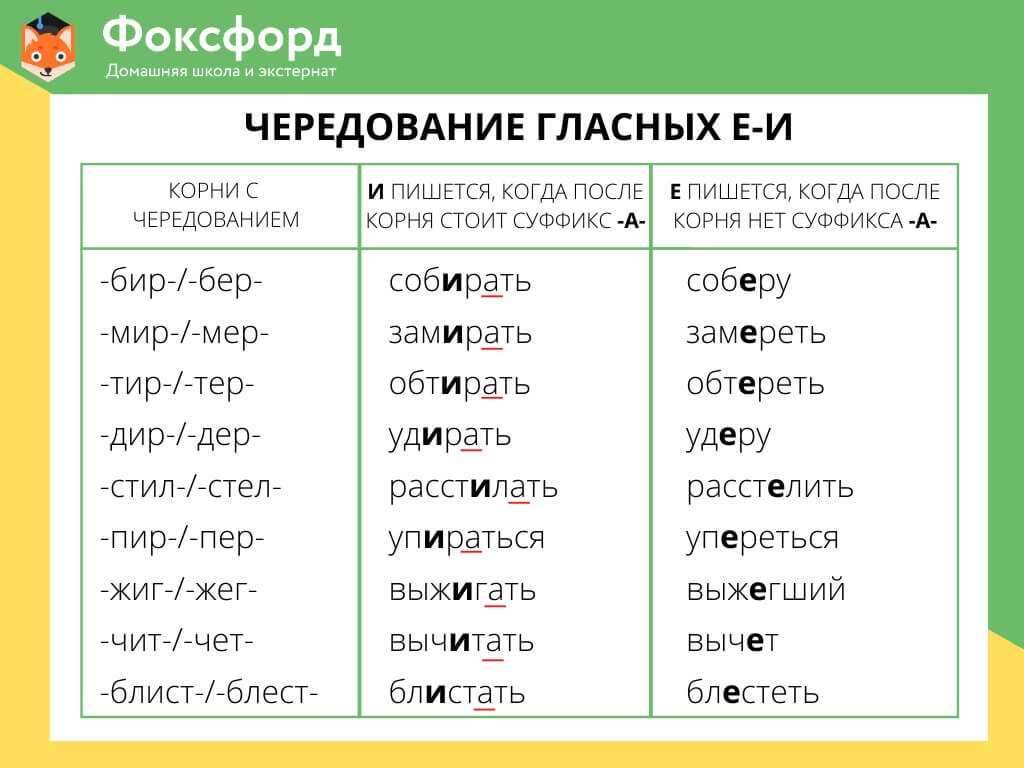
Всего комментариев: 0