Виды суппортов станка: Суппорт токарного станка. Устройство и ремонт суппорта токарного станка
Содержание
что это такое, для чего предназначен
Первый механизированный суппорт, установленный в 1770 году голландцами в машине для сверления пушечных стволов. Качественно изменил все машины и подвинул к новым изобретениям в металлообработке. В мире техники началась новая эпоха.
Содержание:
- 1 Что это такое?
- 2 Принцип работы
- 3 Как он устроен?
- 4 Регулировки
- 5 Как осуществляется его ремонт?
Что это такое?
Суппорт (supporto (лат.) – поддерживаю) – механический держатель резцовой головки станка (токарного, шлифовального, строгального и др.), управляющий режущим инструментом в процессе резания и сообщающий величину подачи в пределах точно установленных допусков.
По степени точности механической подачи и жёсткости суппорта судят о качестве станка.
Принцип работы
Основан на точном перемещении закреплённого в резцедержателе режущего инструмента или обрабатывающего агрегата, или самой заготовки в процессе обработки резанием.
Принцип использования крутящего момента:
- от ходового винта – для нарезания резьбы;
- от ходового вала – для подач режущего инструмента;
- от ходового винта – для нарезания резьбы и, перестроив гитару – для продольной подачи;
- от ручного привода – применяется в операциях, где использование ходового вала и ходового винта не целесообразно (торцевание, снятие фасок, часто – при отрезании детали от заготовки, сверлении и т. д.).
Как он устроен?
Конструкция суппорта состоит из механизмов:
- нижних салазок продольного суппорта;
- поперечных салазок поперечного суппорта с прикрепленной поворотной плитой;
- поворотной плиты с установленным на ней верхним суппортом с резцедержателем;
- фартука.
Продольный суппорт – это салазки (нижние салазки), на которых смонтировано все механизмы агрегата. Привод от ходового вала или ходового винта, посредством коммутирующих устройств, расположенных в фартуке, а также вручную. Нижние салазки суппорта перемещают весь агрегат по направляющим станины.
Нижние салазки суппорта перемещают весь агрегат по направляющим станины.
Поперечный суппорт – механизм, сопряженный с направляющими продольного суппорта. Привод: механический – от винта каретки или вручную. Задаёт направление поворотной плите и верхнему суппорту с резцедержателем.
Поворотная плита закреплена гайкой на поперечных салазках. На поворотной плите установлен механизм верхних салазок (верхнего суппорта).
Верхний суппорт – каретка с салазками (верхние салазки), сопряженными с направляющими поворотной плиты. Поворотная плита предназначена для установки верхнего суппорта под углом к оси поперечных салазок (нарезание конусов).
Резцовая головка (резцедержатель) – установленный на горизонтальной площадке верхних салазок подвижный механизм с четырьмя площадками для крепления режущего инструмента или обрабатывающих агрегатов (напр. – шлифовальная головка) или приспособлений для крепления самой заготовки.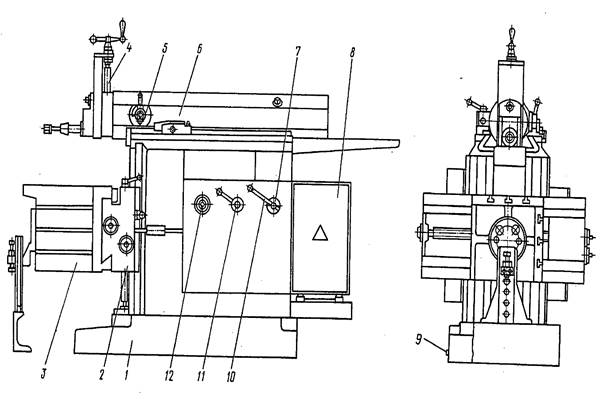
Фартук – основной узел управления всей работы суппорта. На нём смонтированы органы включения – выключения механизмов станка, непосредственно сообщающих величину подачи режущему инструменту.
Механизмы суппорта сообщают режущему инструменту движение в горизонтальной плоскости:
- продольное – вдоль оси заготовки;
- поперечное – под прямым углом относительно оси направляющих станины;
- под заданным углом к продольной оси обрабатываемой детали.
Станки, массой больше 1000 кг, снабжаются устройствами ускоренного перемещения суппорта. Легких станков, как правило, таких устройств лишены, но народные умельцы успешно решают эту проблему самостоятельно.
Регулировки
Любая пара направляющих работает при оптимально достаточной величине зазора между ними. Превышение этой величины понижает жёсткость сопряжений, отрицательно влияет на качество и точность обработки.
Жёсткость поворотного резцедержателя обеспечивается винтовым зажимом и фиксирующим устройством совместно. Если силы фиксирующего устройства недостаточно, возникает опасность разрушения этого ответственного узла от осевых или радиальных нагрузок.
Если силы фиксирующего устройства недостаточно, возникает опасность разрушения этого ответственного узла от осевых или радиальных нагрузок.
Износ трущихся поверхностей суппортов и станин неравномерен и достигает, порой, сотых и даже десятых долей миллиметра. По этой причине невозможно установить одинаковые зазоры на всех рабочих поверхностях. Винты привода салазок изнашиваются также неравномерно.
Для сохранения рабочего диапазона салазок, регулировку зазоров производят с установкой каретки в место с минимальным износом. Направляющие станины интенсивно изнашиваются ближе к передней бабке. Наибольший износ поперечных салазок в середине их рабочего диапазона. Направляющие верхних салазок износу подвержены меньше, поскольку не так часто бывают в работе.
Как осуществляется его ремонт?
Оптимальные значения зазоров во всём рабочем диапазоне сопряжений достижимы средней тяжести и тяжелых станков достижимы исключительно путем восстановления геометрических параметров на шлифовальном станке и шабрением.
Восстановление и реставрация легкого, пусть и морально устаревшего станка, вполне доступны современному умельцу. Приборы электронного управления освобождают от громоздких шкивов, ремней, зубчатых колес и массивных электродвигателей. Шаговые двигатели решают проблему привода суппортов и ходовых винтов. Геометрию и жесткость суппортов осилит любой инструментальный цех.
Поделиться в социальных сетях
Лекция № 2 типы станков с чпу Токарные станки
5
По расположению главного суппорта
станки бывают:
горизонтальные, с сохранением внешнего
сходства с универсальными токарными
станками (16К20РФ3, 16К30Ф3, 16Б16Ф3)вертикальные или наклонные (1П420Ф3). Их
преимуществом является удобство
обслуживания, облегчение уборки стружки,
расположение ходового винта между
направляющими, что способствует
повышению точности перемещения суппорта.
Токарно-револьверные станки могут
быть прутковыми для автоматической
обработки нескольких деталей из прутка
с автоматической подачей заготовок,
или для обработки штучных заготовок в
мелкосерийном и серийном производстве.
Патронные станки предназначены для
выполнения всех видов токарных и
резьбонарезных работ в деталях небольшой
длины типа фланцев, зубчатых колёс,
шкивов. Характерными представителями
таких станков являются полуавтоматы
моделей 1П756ДФ3, КТ141, 1А734Ф3 с горизонтальным
и вертикальным расположением шпинделей.
При использовании промышленных роботов
станок легко встраивается в ГПС и
работает в автоматическом цикле. На
этих станках выполняются все основные
токарные операции и достигается 7-8
квалитет точности.
Широко используются патронные токарные
полуавтоматы модели 1А734Ф3 класса точности
– П. Конструктивной особенностью этого
станка является вертикальная компоновка.
Станок оснащён двумя суппортами с
четырёхпозиционными револьверными
головками. Суппорта выполняют продольные
и поперечные программируемые перемещения
по осям X,Y
и U,W и
позволяют вести обработку одновременно
несколькими инструментами. Станок
оборудован двумя шнековыми транспортёрами
для удаления стружки. Главный привод
Главный привод
имеет бесступенчатое регулирование.
Базовым элементом станка является
основание с закреплёнными на нём двумя
стойками, по направляющим которых
перемещаются два суппорта. Движение
подач осуществляется от высокомоментных
электродвигателей с тормозными муфтами
через передачи винт-гайка качения.
Контроль точности перемещения производится
при помощи бесконтактных концевых
переключателей и преобразователей
пути. Револьверные головки самодействующие,
работают от гидросистемы станка. Поворот
головки может производиться в обе
стороны, что позволяет производить
поиск инструмента по кратчайшей
траектории.
Патронно-центровые станки используются
при обработке деталей с отношением
длины к диаметру больше 5.
На патронно-центровых станках выполняется
наружная и внутренняяобработка сложных
заготовок типа тела вращения. На них
могут обрабатываться как длинные, так
и короткие заготовки, выполняться
операции точения цилиндрических,
конических фасонных наружных и внутренних
поверхностей, сверления и нарезания
внутренних и наружных резьб, совпадающих
с осью вращения. Наиболее распространённые
Наиболее распространённые
станки этого класса 16К20Ф3, 16Б16Ф3, 16К20Т1,
16К30Ф3.Они оснащаются контурными системами
программного управления, многоинструментальными
револьверными головками, транспортёрами
для удаления стружки, автоматическими
зажимными приспособлениями для крепления
заготовок. При установке их в автоматические
линии могут работать в комплексе с
промышленными роботами и другими
автоматическими загрузочными устройствами.
Токарно-карусельные станки используют
для обработки крупных деталей с большим
отношением диаметра к высоте. Они имеют
повышенный класс точности, оснащены
устройствами АСИ. Точность соответствует
7 квалитету. В автоматическом режиме
выполняется точение и растачивание
прямолинейных и криволинейных
поверхностей, обработка торцевых
поверхностей, канавок, выточек, сверление,
зенкерование и развертывание центральных
отверстий, нарезание резьб.
Крупногабаритные станки (См. фотографию)
КУ466 предназначены для обработки деталей
атомных реакторов. Изготавливает
Изготавливает
Коломенское станкостроительное
производственное объединение. Диаметр
обрабатываемой заготовки до 20000 мм.
Масса станка 1125 т.
Карусельные станки применяются для
обработки деталей, у которых диаметр
значительно превосходит их длину. Такие
станки имеют вертикальную ось шпинделя,
и оснащаются продольными и поперечными
суппортами. Карусельные станки выпускаются
одностоечные моделей 1512Ф3, 1А512МФ3,1А516МФ3
и двухстоечные моделей 1А525МФ3, 1А532ЛМФ3.
Дальнейшее повышение производительности
и расширение технологических возможностей
токарных станков с ЧПУ идет за счет
концентрации операций, увеличения
количества револьверных головок и
суппортов, повышения жесткости конструкции
за счет новых компоновок (наклонные
станины) (см. рис. 5.1, стр. 175, Кузнецов).
При обработке на станке традиционной
конструкции невозможно вести обработку
одновременно более чем двумя инструментами,
т.к. существует только два независимых
суппорта продольный и поперечный (рис.
5.2,а, стр. 176)
Современные центровые станки позволяют
обрабатывать вал одновременно с двух
сторон при закреплении за среднюю часть
и с торца (рис. 5.2,б,в, стр. 176) При
размещении шпиндельной бабки между
центрами (рис.в) можно вести обработку
длинных деталей с высокой точностью и
использовать четыре суппорта.
Новые компоновки станков имеют четыре-пять
суппортов, которые работают по принципу
разделения припуска по глубине или
длине (рис. 5.2,г,д, стр. 176)
Двухшпиндельные станки
Примером токарного двухшпиндельного
патронного станка является станок
МР315, разработанный Московским ПО
Станкостроительный завод им. Ордженикидзе.
(рис. 5.17, стр.202). Наибольший диаметр
детали 500 мм. Станок имеет две независимые
друг от друга стороны с самостоятельными
системами управления. Каждый шпиндель
имеет свою револьверную головку. По
желанию покупателя станок может быть
оснащен автооператором или портальным
роботом.
Используются двухшпиндельные
станки-автоматы с противоположным
расположением шпинделей, что позволяет
обрабатывать деталь с двух сторон в
автоматическом режиме. Загрузка в левый
шпиндель осуществляется загрузочным
устройством, а в правый – путем
автоматического перемещения правой
шпиндельной бабки. Разжим и зажим
заготовки автоматизирован. Станок
оснащен двумя суппортами с десятипозиционной
револьверной головкой каждый (рис.
5.19, стр.204, Кузнецов). Такая компоновка
позволяет сократить время обработки
на 60%.
Киевским станкостроительным концерном
освоен выпуск двухшпиндельных токарных
станков серии ПАБ. Станок модели ПАБ-160
предназначен для обработки заготовок
диаметром до 180 мм. На станке установлены
два оппозитно расположенных шпинделя,
между которыми расположен крестовый
суппорт.
Обработка выполняется последовательно
на одном и на другом шпинделе. Это
позволяет вести непрерывную обработку,
так как загрузка и разгрузка одного
шпинделя выполняется в то время, когда
на другом ведётся обработка. Станки
Станки
оснащаются встроенной транспортной
системой, датчиками положения режущей
кромки инструмента, системой контроля
затупления и поломки инструмента. На
станке установлена система программного
управления Siemens Sinumerik
802D.
Оригинальное конструктивное решение
предложено в другом токарном станке
этой же серии. Станок модели ПАБ-350
предназначен для обработки деталей
типа колец, фланцев из штучных заготовок
в условиях мелко-, средне- и крупносерийного
производства. Отличительной особенностью
станка ПАБ-350 является вертикальное
расположение шпинделя над неподвижно
установленным инструментом. На литом
основании на жёстких подставках
монтируется траверса с продольными
направляющими крестовых суппортов.
Крестовый суппорт состоит из продольных
и поперечных салазок с направляющими
качения. На суппорте устанавливается
шпиндельная бабка с приводом главного
движения. Система управления станка
обеспечивает независимое вращение
шпинделей по осям С1 и С2 и перемещение
каждого суппорта по осям X1,X2
и Z1,Z2.
Обработка выполняется
последовательно на двух суппортах.
Первый суппорт имеет возможность выхода
в зону входного лотка для взятия
заготовки. При перемещении суппорта в
поперечном направлении примерно в
середине хода происходит обработка
детали режущим инструментом, установленным
в инструментальном блоке. Затем суппорт
перемещается в зону передачи заготовки,
где происходит передача обработанной
на первом шпинделе заготовки для
установки на второй шпиндель. В середине
рабочего хода второго суппорта так же
происходит обработка, затем он выходит
в зону отводящего лотка для удаления
обработанной детали из зоны обработки.
Передача заготовки с одного шпинделя
на другой осуществляется с переворотом
заготовки или без переворота специальным
передающим устройством. Два инструментальных
блока устанавливаются на станине и
могут оснащаться датчиком касания для
выполнения операции привязки инструмента.
В конструкции станка предусмотрена
возможность установки револьверных
головок и вращающегося инструмента,
что позволяет значительно расширить
технологические возможности станка.
Поддерживаемые типы машин | Документация Dataproc
Кластеры Dataproc построены на Compute Engine
экземпляры. Типы машин определяют виртуализированное оборудование
ресурсы, доступные экземпляру. Compute Engine предлагает как предопределенные
типы машин и
пользовательские типы машин.
Кластеры Dataproc могут использовать как предопределенные, так и пользовательские типы для
как главные, так и/или рабочие узлы.
Dataproc поддерживает следующие предварительно определенные Compute Engine
типы машин в кластерах:
Примечание: Доступность типов машин зависит от региона. См. Типы машин для получения информации о конкретных типах машин.
- Типы машин общего назначения,
включая типы машин N1, N2, N2D и E2: Dataproc также поддерживает N1, N2, N2D и E2
пользовательские типы машин.
Ограничения:- тип машины n1-standard-1 не поддерживается для образов 2.0+
- тип машины n1-standard-1 не рекомендуется для версий до 2.
 0
0
изображения — пользователи должны использовать тип машины с большим объемом памяти - Типы машин с общим ядром не поддерживаются , который
включают следующие неподдерживаемые типы машин:- E2: типы машин с общим ядром e2-micro, e2-small и e2-medium
- N1: машины с общим ядром f1-micro и g1-small
Типы машин, оптимизированных для вычислений,
которые включают типы машин C2.Типы машин с оптимизацией памяти,
которые включают типы машин M1 и M2.
Справку по выбору типа машины см. в разделе Оптимизация затрат Dataproc с использованием типа машины VM.
Пользовательские типы машин
Пользовательские типы машин
идеально подходят для следующих рабочих нагрузок:
- Рабочие нагрузки, которые не подходят для предопределенных типов машин.
- Рабочие нагрузки, требующие большей вычислительной мощности или памяти, но не требующие
все обновления, предоставляемые следующим уровнем типа машины.
Например, если у вас есть рабочая нагрузка, требующая большей вычислительной мощности, чем
который предоставляется экземпляром n1-standard-4 , но следующим шагом является экземпляр n1-стандарт-8
например, обеспечивает слишком большую емкость. С пользовательскими типами машин вы можете создавать кластеры Dataproc с главными и/или рабочими узлами в середине.
диапазон, с 6 виртуальными процессорами и 25 ГБ памяти.
Указание нестандартного типа машины
Нестандартные типы машин используют специальную спецификацию типа машины и подлежат
к ограничениям. Например,
спецификация пользовательского типа машины для пользовательской виртуальной машины с 6 виртуальными ЦП и
22,5 Гб памяти это custom-6-23040 .
Числа в спецификации типа машины соответствуют количеству виртуальных ЦП
(vCPU) в машине ( 6 ) и объем памяти ( 23040 ).
Объем памяти рассчитывается путем умножения объема памяти в
гигабайт на 1024 (см.
Выражение памяти в ГБ или МБ). В этом примере 22,5 (ГБ) умножается на 1024: 22,5 * 1024 = 23040 .
Примечание. Dataproc требует, чтобы типы машин имели не менее 3,5 ГБ.
(3584) памяти.
Вы используете приведенный выше синтаксис для указания пользовательского типа машины с вашими кластерами.
Вы можете установить тип машины для главного или рабочего узла, или для обоих, когда вы
создать кластер. Если вы установите оба параметра, главный узел может использовать пользовательский тип машины.
который отличается от пользовательского типа машины, используемого рабочими. Тип машины
используемые любыми вторичными рабочими, следуйте настройкам для основных рабочих и
нельзя установить отдельно (см.
Secondary worker — вытесняемые и не вытесняемые виртуальные машины).
См. Расширенную память ЦП
для увеличения памяти процессора выше стандартных пределов.
Ценообразование
Ценообразование нестандартного типа машины
основан на ресурсах, используемых на пользовательской машине. Цены Dataproc добавляются к стоимости вычислительных ресурсов и основаны на
общее количество виртуальных ЦП (vCPU), используемых в кластере.
Создать кластер Dataproc с указанным типом машины
Команда gcloud
Запустите
Кластеры gcloud dataproc создают
команда со следующими флагами для создания кластера Dataproc с мастером
и/или типы рабочих машин:
--master-machine-type machine-type
флаг позволяет вам установить предопределенный или пользовательский тип машины, используемый мастером
Экземпляр виртуальной машины в вашем кластере (или главные экземпляры, если вы создаете
Кластер высокой доступности)-
--worker-machine-type custom-machine-type
флаг позволяет вам установить предопределенный или пользовательский тип машины, используемый воркером
Экземпляры ВМ в вашем кластере
Пример :
Кластеры gcloud dataproc создают тестовый кластер / --master-machine-type custom-6-23040 / --worker-machine-type custom-6-23040 / другие аргументы
Простой способ изучить и построить
команда gcloud cluster create предназначена для открытия
Dataproc Создать кластер
страницу в консоли Google Cloud, заполните соответствующие поля на странице,
затем нажмите Эквивалентная командная строка
в нижней части левой панели страницы Создать кластер для просмотра, копирования и
вставьте завершенную команду gcloud .
После запуска кластера Dataproc сведения о кластере отображаются в
окно терминала. Ниже приведен частичный образец списка свойств кластера.
отображается в окне терминала:
... характеристики: distcp:mapreduce.map.java.opts: -Xmx1638m distcp:mapreduce.map.memory.mb: '2048' distcp:mapreduce.reduce.java.opts: -Xmx4915m distcp:mapreduce.reduce.memory.mb: '6144' mapred:mapreduce.map.cpu.vcores: '1' mapred:mapreduce.map.java.opts: -Xmx1638m ...
REST API
Чтобы создать кластер с пользовательскими типами машин, установите
machineTypeUri в masterConfig и/или workerConfig
Конфигурация группы экземпляров
в
кластер.создать
Запрос API.
Пример :
POST /v1/projects/my-project-id/regions/is-central1/clusters/
{
"projectId": "мой-проект-id",
"имя_кластера": "тест-кластер",
"конфигурация": {
"configBucket": "",
"gceClusterConfig": {
"subnetworkUri": "по умолчанию",
"zoneUri": "us-central1-a"
},
"МастерКонфиг": {
"количество экземпляров": 1,
"machineTypeUri": "n1-highmem-4" ,
"дискконфиг": {
"бутдисксизегб": 500,
"numLocalSsds": 0
}
},
"рабочая конфигурация": {
"количество экземпляров": 2,
"machineTypeUri": "n1-highmem-4" ,
"дискконфиг": {
"бутдисксизегб": 500,
"numLocalSsds": 0
}
}
}
}
Простой способ изучить и создать тело JSON для
Кластеры Dataproc API создают запрос на открытие
Dataproc Создать кластер
в консоли Google Cloud, заполните соответствующие поля на странице, затем нажмите
Эквивалент REST в нижней части левой панели страницы Создать кластер для
просмотрите, скопируйте и вставьте запрос POST с заполненным телом запроса JSON.
Консоль
На панели «Настроить узлы» Dataproc
Создать кластерную страницу
в консоли Google Cloud выберите семейство, серию и тип машины для
главный и рабочий узлы кластера.
CPU Extended Memory
Dataproc поддерживает пользовательские типы машин с
расширенная память
вне
6,5 ГБ на виртуальный ЦП
(см. Цены на расширенную память).
Несмотря на отсутствие ограничений на объем расширенной памяти на ЦП,
есть лимит на сумму
расширенная память на экземпляр виртуальной машины.
Использование расширенной памяти
Команда gcloud
Чтобы создать кластер из командной строки gcloud с помощью
пользовательских процессоров с расширенной памятью, добавьте суффикс -ext к
— мастер-машина типа и/или
— флаги рабочей машины типа .
Пример
Следующий пример командной строки gcloud создает
Кластер Dataproc с 1 ЦП и 50 ГБ памяти (50 * 1024 = 51200) в каждом
узел:
Кластеры gcloud dataproc создают тестовый кластер / --master-machine-type custom-1-51200-ext / --worker-machine-type custom-1-51200-ext / другие аргументы
REST API
Следующий образец фрагмента JSON из REST API Dataproc
кластеры.создать
запрос указывает 1 ЦП и 50 ГБ памяти (50 * 1024 = 51200) в каждом узле:
...
"МастерКонфиг": {
"количество экземпляров": 1,
"machineTypeUri": "custom-1-51200-ext",
...
},
"рабочая конфигурация": {
"количество экземпляров": 2,
"machineTypeUri": "custom-1-51200-ext",
...
...
Консоль
Нажмите Расширить память при настройке памяти типа машины в
Раздел «Главный узел» и/или «Рабочие узлы» в Dataproc
Создать кластер
страницу в консоли Google Cloud.
См. Создание экземпляра ВМ с пользовательским типом машины.
Все, что вам нужно знать о машинах опорных векторов
Машина опорных векторов (SVM) определяется как алгоритм машинного обучения, который использует модели обучения с учителем для решения сложных задач классификации, регрессии и обнаружения выбросов путем выполнения оптимальных преобразований данных которые определяют границы между точками данных на основе предопределенных классов, меток или выходных данных. В этой статье объясняются основы SVM, их работа, типы и несколько реальных примеров.
Содержание
- Что такое метод опорных векторов?
- Как работает машина опорных векторов?
- Типы машин опорных векторов
- Примеры машин опорных векторов
Что такое метод опорных векторов?
Машина опорных векторов (SVM) — это алгоритм машинного обучения, который использует модели обучения с учителем для решения сложных задач классификации, регрессии и обнаружения выбросов путем выполнения оптимальных преобразований данных, которые определяют границы между точками данных на основе предварительно определенных классов, меток или выходы. SVM широко используются в таких областях, как здравоохранение, обработка естественного языка, приложения для обработки сигналов и области распознавания речи и изображений.
SVM широко используются в таких областях, как здравоохранение, обработка естественного языка, приложения для обработки сигналов и области распознавания речи и изображений.
Технически основная цель алгоритма SVM состоит в том, чтобы идентифицировать гиперплоскость, которая четко разделяет точки данных разных классов. Гиперплоскость локализована таким образом, что наибольший запас разделяет рассматриваемые классы.
Представление опорного вектора показано на рисунке ниже:
SVM оптимизируют границу между опорными векторами или классами
гиперплоскость без каких-либо внутренних опорных векторов. Такие гиперплоскости легче определить для линейно разделимых задач; однако для реальных задач или сценариев алгоритм SVM пытается максимизировать разницу между опорными векторами, тем самым приводя к неправильным классификациям для меньших участков точек данных.
SVM потенциально предназначены для решения задач двоичной классификации. Однако с ростом количества многоклассовых задач, требующих больших вычислительных ресурсов, создается несколько бинарных классификаторов, которые объединяются для формулировки SVM, которые могут реализовывать такие многоклассовые классификации с помощью двоичных средств.
Однако с ростом количества многоклассовых задач, требующих больших вычислительных ресурсов, создается несколько бинарных классификаторов, которые объединяются для формулировки SVM, которые могут реализовывать такие многоклассовые классификации с помощью двоичных средств.
В математическом контексте SVM относится к набору алгоритмов машинного обучения, которые используют методы ядра для преобразования характеристик данных с помощью функций ядра. Функции ядра основаны на процессе сопоставления сложных наборов данных с более высокими измерениями таким образом, чтобы упростить разделение точек данных. Функция упрощает границы данных для нелинейных задач, добавляя более высокие измерения для отображения сложных точек данных.
При введении дополнительных измерений данные не полностью преобразуются, поскольку они могут действовать как вычислительный процесс. Этот метод обычно называют уловкой ядра, при котором преобразование данных в более высокие измерения достигается эффективно и недорого.
Идея алгоритма SVM была впервые сформулирована в 1963 году Владимиром Н. Вапником и Алексеем Я. Червоненкис. С тех пор SVM приобрели достаточную популярность, поскольку они продолжают иметь широкомасштабное применение в нескольких областях, включая процесс сортировки белков, категоризацию текста, распознавание лиц, автономные автомобили, роботизированные системы и так далее.
Узнать больше: Что такое нейронная сеть? Определение, работа, типы и приложения в 2022 году
Как работает машина опорных векторов?
Работу машины опорных векторов можно лучше понять на примере. Предположим, у нас есть красные и черные метки с функциями, обозначенными x и y. Мы намерены иметь классификатор для этих тегов, который классифицирует данные либо по красной, либо по черной категории.
Давайте нанесем размеченные данные на плоскость x-y, как показано ниже:
Типичный SVM разделяет эти точки данных на красные и черные теги с помощью гиперплоскости, которая в данном случае является двумерной линией. Гиперплоскость обозначает линию границы решения, в которой точки данных попадают под красную или черную категорию.
Гиперплоскость обозначает линию границы решения, в которой точки данных попадают под красную или черную категорию.
Гиперплоскость определяется как линия, которая расширяет поля между двумя ближайшими тегами или метками (красной и черной). Расстояние от гиперплоскости до ближайшей метки является наибольшим, что упрощает классификацию данных.
Приведенный выше сценарий применим к линейно разделимым данным. Однако для нелинейных данных простая прямая линия не может разделить отдельные точки данных.
Вот пример нелинейного сложного набора данных:
Приведенный выше набор данных показывает, что одной гиперплоскости недостаточно для разделения задействованных меток или тегов. Однако здесь векторы явно различаются, что облегчает их разделение.
Для классификации данных необходимо добавить еще одно измерение в пространство признаков. Для линейных данных, обсуждавшихся до этого момента, было достаточно двух измерений x и y. В этом случае мы добавляем z-размер, чтобы лучше классифицировать точки данных. Более того, для удобства воспользуемся уравнением для окружности z = x² + y².
Более того, для удобства воспользуемся уравнением для окружности z = x² + y².
С третьим измерением срез пространства признаков вдоль направления z выглядит следующим образом:
Теперь, с тремя измерениями, в этом случае гиперплоскость проходит параллельно направлению x при определенном значении z; давайте рассмотрим это как z = 1.
Остальные точки данных дополнительно сопоставляются с двумя измерениями.
На приведенном выше рисунке показана граница для точек данных вдоль объектов x, y и z вдоль окружности с радиусом 1 единица, которая разделяет две метки тегов через SVM.
Давайте рассмотрим другой метод визуализации точек данных в трех измерениях для разделения двух тегов (в данном случае двух теннисных мячей разного цвета). Рассмотрим шары, лежащие на двумерной плоской поверхности. Теперь, если мы поднимем поверхность вверх, все теннисные мячи будут распределены в воздухе. Два шара разного цвета могут разделиться в воздухе в какой-то момент этого процесса.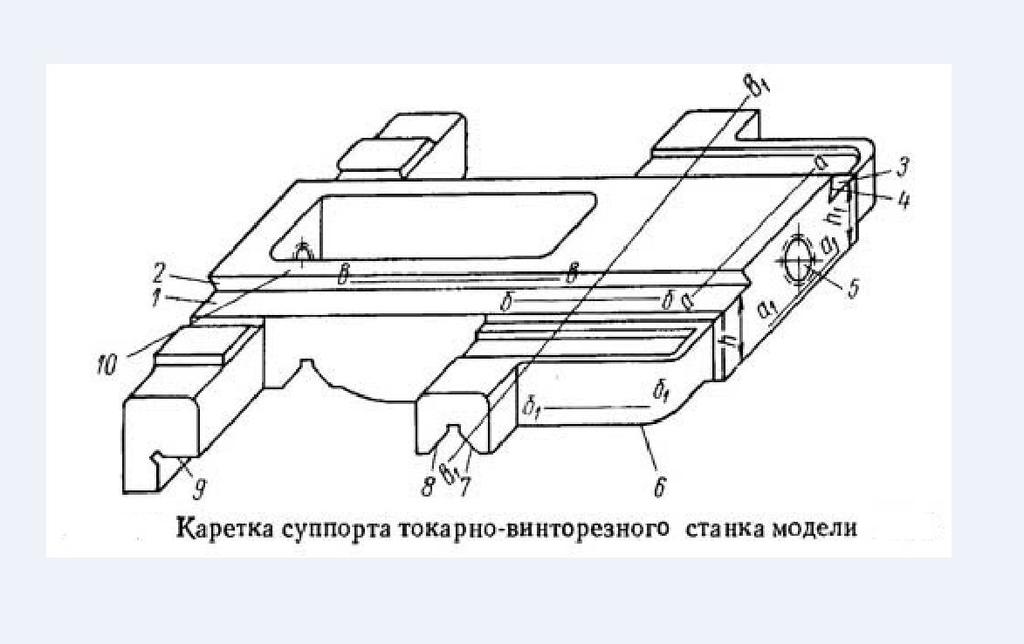 Пока это происходит, вы можете использовать или поместить поверхность между двумя отдельными наборами шариков.
Пока это происходит, вы можете использовать или поместить поверхность между двумя отдельными наборами шариков.
Во всем этом процессе акт «подъема» 2D-поверхности относится к событию отображения данных в более высокие измерения, что технически называется «кернеллингом», как упоминалось ранее. Таким образом, сложные точки данных могут быть разделены с помощью большего количества измерений. Подчеркнутая здесь концепция заключается в том, что точки данных продолжают отображаться в более высоких измерениях до тех пор, пока не будет идентифицирована гиперплоскость, которая показывает четкое разделение между точками данных.
На рисунке ниже представлена трехмерная визуализация описанного выше варианта использования:
Подробнее: Узкий ИИ, общий ИИ и супер-ИИ: ключевые сравнения
Типы машин опорных векторов
можно разделить на два типа: простой или линейный SVM и ядерный или нелинейный SVM.
1. Простой или линейный SVM
Линейный SVM относится к типу SVM, используемому для классификации линейно разделимых данных. Это означает, что когда набор данных можно разделить на категории или классы с помощью одной прямой линии, он называется линейным SVM, а данные называются линейно различными или разделимыми. Более того, классификатор, который классифицирует такие данные, называется линейным классификатором SVM.
Это означает, что когда набор данных можно разделить на категории или классы с помощью одной прямой линии, он называется линейным SVM, а данные называются линейно различными или разделимыми. Более того, классификатор, который классифицирует такие данные, называется линейным классификатором SVM.
Простой SVM обычно используется для решения задач классификации и регрессионного анализа.
2. Ядро или нелинейный SVM
Нелинейные данные, которые нельзя разделить на отдельные категории с помощью прямой линии, классифицируются с использованием ядра или нелинейного SVM. Здесь классификатор называется нелинейным классификатором. Классификацию можно выполнять с нелинейным типом данных, добавляя признаки в более высокие измерения, а не полагаясь на двумерное пространство. Здесь недавно добавленные функции соответствуют гиперплоскости, которая помогает легко разделять классы или категории.
SVM ядра обычно используются для решения задач оптимизации с несколькими переменными.
Подробнее : Что такое анализ настроений? Определение, инструменты и приложения
Примеры машин опорных векторов
SVM полагаются на контролируемые методы обучения для классификации неизвестных данных по известным категориям. Они находят применение в различных областях.
Здесь мы рассмотрим некоторые из лучших реальных примеров SVM:
1. Решение проблемы геозондирования
Проблема геозондирования — один из широко распространенных вариантов использования SVM, в котором процесс используется для отслеживания многоуровневой структуры планеты. Это влечет за собой решение проблем инверсии, когда наблюдения или результаты проблем используются для факторизации переменных или параметров, которые их произвели.
В процессе линейная функция и алгоритмические модели опорных векторов разделяют электромагнитные данные. Кроме того, в этом случае при разработке моделей с учителем используются методы линейного программирования. Поскольку размер задачи значительно мал, размер измерения неизбежно будет крошечным, что объясняет картографирование структуры планеты.
Поскольку размер задачи значительно мал, размер измерения неизбежно будет крошечным, что объясняет картографирование структуры планеты.
2. Оценка потенциала сейсмического разжижения
Разжижение грунта является серьезной проблемой, когда происходят такие события, как землетрясения. Оценка его потенциала имеет решающее значение при проектировании любой гражданской инфраструктуры. SVM играют ключевую роль в определении появления и отсутствия таких аспектов разжижения. Технически SVM выполняют два теста: SPT (стандартное испытание на проникновение) и CPT (испытание на конусное проникновение), которые используют полевые данные для оценки сейсмического статуса.
Кроме того, SVM используются для разработки моделей, включающих несколько переменных, таких как факторы грунта и параметры разжижения, для определения прочности поверхности грунта. Считается, что SVM достигают точности, близкой к 96-97% для таких приложений.
3. Дистанционное обнаружение гомологии белков
Дистанционная гомология белков — это область вычислительной биологии, в которой белки классифицируются по структурным и функциональным параметрам в зависимости от последовательности аминокислот, когда идентификация последовательности кажется затруднительной.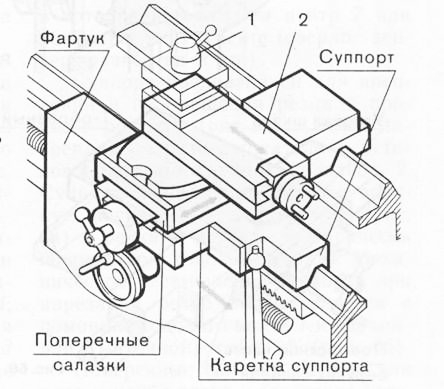 SVM играют ключевую роль в удаленной гомологии, при этом функции ядра определяют общность между белковыми последовательностями.
SVM играют ключевую роль в удаленной гомологии, при этом функции ядра определяют общность между белковыми последовательностями.
Таким образом, SVM играют определяющую роль в вычислительной биологии.
4. Классификация данных
Известно, что SVM решают сложные математические задачи. Однако сглаженные SVM предпочтительнее для целей классификации данных, в которых используются методы сглаживания, которые уменьшают выбросы данных и делают шаблон идентифицируемым.
Таким образом, для задач оптимизации гладкие SVM используют алгоритмы, такие как алгоритм Ньютона-Армиджо, для обработки больших наборов данных, которые не могут использовать обычные SVM. Гладкие типы SVM обычно используют математические свойства, такие как сильная выпуклость, для более простой классификации данных, даже с нелинейными данными.
5. Обнаружение лиц и классификация выражений
SVM классифицируют лицевые структуры по сравнению с не-лицевыми. В обучающих данных используются два класса объекта лица (обозначается +1) и объекта без лица (обозначается -1) и n * n пикселей, чтобы различать структуры лица и не лица. Далее анализируется каждый пиксель, и из каждого извлекаются признаки, обозначающие лицевые и нелицевые символы. Наконец, процесс создает квадратную границу решения вокруг лицевых структур на основе интенсивности пикселей и классифицирует полученные изображения.
Далее анализируется каждый пиксель, и из каждого извлекаются признаки, обозначающие лицевые и нелицевые символы. Наконец, процесс создает квадратную границу решения вокруг лицевых структур на основе интенсивности пикселей и классифицирует полученные изображения.
Кроме того, SVM также используются для классификации выражений лица, которая включает выражения, обозначаемые как счастливые, грустные, сердитые, удивленные и так далее.
6. Классификация текстуры поверхности
В текущем сценарии SVM используются для классификации изображений поверхностей. Подразумевается, что изображения поверхностей, на которые нажимают, могут быть переданы в SVM для определения текстуры поверхностей на этих изображениях и классификации их как гладких или шероховатых поверхностей.
7. Категоризация текста и распознавание рукописного ввода
Категоризация текста относится к классификации данных по предопределенным категориям. Например, новостные статьи содержат информацию о политике, бизнесе, фондовом рынке или спорте. Точно так же можно разделить электронные письма на спам, не спам, нежелательную почту и другие.
Точно так же можно разделить электронные письма на спам, не спам, нежелательную почту и другие.
Технически каждой статье или документу присваивается оценка, которая затем сравнивается с предопределенным пороговым значением. Статья классифицируется в соответствующую категорию в зависимости от оцененного балла.
Для примеров распознавания рукописного ввода набор данных, содержащий отрывки, написанные разными людьми, передается в SVM. Как правило, классификаторы SVM сначала обучаются на выборочных данных, а затем используются для классификации почерка на основе значений баллов. Впоследствии SVM также используются для разделения текстов, написанных людьми и компьютерами.
8. Распознавание речи
В примерах распознавания речи слова из речи выбираются и разделяются по отдельности. Далее для каждого слова извлекаются определенные признаки и характеристики. Методы извлечения признаков включают кепстральные коэффициенты частоты Mel (MFCC), коэффициенты линейного предсказания (LPC), кепстральные коэффициенты линейного предсказания (LPCC) и другие.
Эти методы собирают аудиоданные, передают их в SVM, а затем обучают модели распознаванию речи.
9. Обнаружение стенографии
С помощью SVM вы можете определить, является ли какое-либо цифровое изображение искаженным, загрязненным или чистым. Такие примеры полезны при решении вопросов, связанных с безопасностью, для организаций или государственных учреждений, поскольку проще шифровать и вставлять данные в качестве водяного знака в изображения с высоким разрешением.
Такие изображения содержат больше пикселей; следовательно, может быть сложно обнаружить скрытые сообщения или сообщения с водяными знаками. Однако одним из решений является разделение каждого пикселя и сохранение данных в разных наборах данных, которые впоследствии могут быть проанализированы SVM.
10. Обнаружение рака
Медицинские работники, исследователи и ученые во всем мире усердно работают над поиском решения, позволяющего эффективно обнаруживать рак на ранних стадиях. Сегодня для этого используется несколько инструментов AI и ML. Например, в январе 2020 года Google разработала инструмент искусственного интеллекта, который помогает в раннем выявлении рака молочной железы и снижает количество ложных срабатываний и отрицательных результатов.
Сегодня для этого используется несколько инструментов AI и ML. Например, в январе 2020 года Google разработала инструмент искусственного интеллекта, который помогает в раннем выявлении рака молочной железы и снижает количество ложных срабатываний и отрицательных результатов.
В таких примерах можно использовать SVM, в которых раковые изображения могут подаваться в качестве входных данных. Алгоритмы SVM могут анализировать их, обучать модели и, в конечном итоге, классифицировать изображения, которые выявляют признаки злокачественного или доброкачественного рака.
Подробнее : Что такое дерево решений? Алгоритмы, шаблоны, примеры и лучшие практики
Вывод
SVM имеют решающее значение при разработке приложений, включающих реализацию прогностических моделей. SVM легко понять и развернуть. Они предлагают сложный алгоритм машинного обучения для обработки линейных и нелинейных данных через ядра.
SVM находят применение в любой области и в реальных сценариях, где данные обрабатываются путем добавления многомерных пространств.
Всего комментариев: 0