Блог сканеры: 3D-технологии. Блог iQB technologies. 3D-принтеры и 3D-сканеры профессиональные и промышленные, 3d печать, 3d сканирование, 3d решения в Москве
3D-технологии. Блог iQB technologies. 3D-принтеры и 3D-сканеры профессиональные и промышленные, 3d печать, 3d сканирование, 3d решения в Москве
Реверс-инжинирингЭксперты рекомендуют
| Время чтения: 6 минут
5 преимуществ фотополимеров
Основы 3DБыстрое прототипирование
| Время чтения: 5 минут
17 передовых программ для обработки данных 3D‑сканирования
Контроль геометрииПрограммное обеспечениеЛучшее по темам
| Время чтения: 11 минут
Как выбрать 3D-сканер
3D-сканерыКонтроль геометрииЛучшее по темам
| Время чтения: 6 минут
От воска до металла: обзор основных материалов для 3D-печати
Основы 3DБыстрое прототипирование
| Время чтения: 9 минут
Технология селективного лазерного плавления (SLM)
Основы 3DТопологическая оптимизация
| Время чтения: 6 минут
Что такое Binder Jetting и как изготовить литейную форму за сутки
Основы 3DЛитье3D-принтеры
| Время чтения: 7 минут
Один к одному: SLA‑технология помогает создать реалистичный прототип спорткара
Истории внедренияАвтомобилестроениеБыстрое прототипирование
| Время чтения: 5 минут
Подпишитесь на блог
Нажимая на кнопку «Подписаться», вы принимаете условия Политики обработки персональных данных
Выставка Testing & Control 2022: всё под 3D‑контролем
3D-сканерыКонтроль геометрииПрограммное обеспечение
| Время чтения: 6 минут
ABS‑пластик в аддитивном производстве: полезные советы
Основы 3DБыстрое прототипирование
| Время чтения: 8 минут
Наземный 3D‑сканер начального уровня: 12 главных вопросов
3D-сканерыСтроительство и архитектураЭксперты рекомендуют
| Время чтения: 9 минут
Приглашаем на выставку Testing & Control 2022
Контроль геометрии
| Время чтения: 2 минуты
3D‑принтер по металлу – превосходный инструмент для ортопедов
Истории внедренияМедицина
| Время чтения: 5 минут
5 рисков, угрожающих бизнесу при использовании пиратского ПО
Аналитика и бизнесПрограммное обеспечение
| Время чтения: 6 минут
Литье пластиков под давлением: ускоряем контроль качества в десятки раз
ЛитьеКонтроль геометрии
| Время чтения: 5 минут
3D‑печать полимерами в России: от разработки до внедрения в производство, часть 2
Быстрое прототипированиеЭксперты рекомендуют
| Время чтения: 7 минут
<
1
2
3
4
5
. ..
..
38
>
Протяжный сканер — что это
- Компьютерный магазин
- Блог
- Статьи на тему: Сканеры (scanner)
Автор статьи: Сергей Коваль
([email protected])
Опубликовано: 20 июня 2022
Протяжный сканер представляет собой скоростное устройство, которое выглядит как принтер небольших размеров
Протяжный сканер справляется с скоростной оцифровкой намного лучше по отношению к своим цифровым собратьям. Для работы с оборудованием нужны бумажные документы, не подверженные каким-либо деформациям: смятие, заломы, водные пятна и т.д. Кроме того, листы бумаги не должны иметь скоб от степлера и иных металлических скрепок.
Устройство данного типа рассчитано на огромный поток нагрузки. Функция автоподачи выполняется безостановочно, что благоприятно сказывается на скорости работы оборудования.
Но, отметим, что перегружать протяжный сканер крайне нежелательно. Это может вызвать перегрев устройства и его возможную поломку. Чтобы срок службы был долгим, следует обязательно ознакомиться с техническими характеристиками оборудования в прилагаемой к нему инструкции. Следуя указанным в ней правилам, принтер сохранит свои функциональные свойства и будет менее подвержен быстрому износу.
Рассмотрим ниже основные характеристики протяжного сканера.
Дуплекс и цвет
Современные модели протяжных устройств оснащены режимами цветного и двустороннего сканирования документов. Для многих пользователей этот достаточно важные характеристики, необходимые в сфере их деятельности.
Отметим, что некоторые устаревшие версии данными функциями не оснащены. Поэтому, при выборе оборудования из такого сегмента следует внимательнее изучать технические параметры устройства.
Производительность
Большинства моделей офисного назначения имеют автоподатчик с лотком, емкость которого рассчитана примерно на 65 листов. При этом скорость сканирования может достигать 100 страницам в минуту.
При этом скорость сканирования может достигать 100 страницам в минуту.
Скорость сканирования также зависит от того, в каком цвете это выполняется. В цветном режиме производительность устройства снижается относительно черно-белого, но не критично.
При использовании портативного протяжного сканера, у которого отсутствует свойство автоподачи, производительность устройства зависит от скорости добавления документов в оборудование.
Программное обеспечение
В комплект с протяжным сканером прилагается диск с программным обеспечением для операционных систем Windows и MacOS. Оно обеспечивает режим сканирования, сохранения, обработки и вывода на печать полученного изображения.
Отметим, что данный софт индивидуален для каждого типа устройства. Но помимо ПО в комплекте оборудования, также существуют и предложения на рынке, включающие большой выбор программных и аппаратных решений для различных моделей протяжных сканеров.
Драйверы
Кроме диска со специализированным ПО, в комплекте устройства также идут драйверы, необходимые для правильного распознавания оборудования при подключении его к ПК или ноутбуку.
В основном набор драйверов зависит от конкретной модели сканера. Но на практике существуют и универсальные софты для взаимодействия ОС и компьютера. Обычно это стандарты: ISIS, WIA, TWAIN.
Тип сканируемых документов
Протяжный сканер способен сканировать:
- фотографии;
- текстовые документы;
- квитанции и чеки;
- визитки и т.п.
Полный функционал зависит от конкретной модели оборудования. Также значение имеет допустимый формат документов и плотность бумажного носителя.
Большинство протяжных сканеров оснащены режимом настройки профилей для различных типов сканируемой документации. Это необходимо для получения максимально точных результатов отображения информации.
Отметим, что протяжные сканеры не предназначены для работы со сшитыми и сброшюрованными оригиналами. Для этих целей используется специальное комбинированное оборудование со встроенным планшетом.
Оптическое распознавание символов
Большинство современных протяжных сканеров отлично сканируют и конвертируют печатные носители информации. Такое свойство позволяет работать с документами в текстовом редакторе сразу же после сканирования.
Кроме того, после отображения документа на ПК, есть возможность его преобразования в формат PDF+text или searchable PDF. Такой тип файлов характеризуется возможностью полнотекстового поиска и востребован в области хранения на различных электронных системах.
Пару слов в заключение статьи
В окончание статьи отметим, что протяжный сканер относится к устройствам автоматизированной работы с большим объемом документов. Ролики системы автоподачи протягивают сканируемый оригинал перед неподвижной фотосчитывающей системой. В результате этого происходит преобразование отраженного от поверхности документа света в последовательность электронных импульсов.
В результате этого происходит преобразование отраженного от поверхности документа света в последовательность электронных импульсов.
Модели протяжных сканеров разделяются на уровни в зависимости от скорости сканирования и рассчитанной суточной нагрузки на оборудование. Но назначение абсолютно всех устройств такое типа заключается в работе с большим потоком документов. В связи с этим, некоторые специалисты называют протяжные сканеры поточными.
На практике данное оборудование в основном встречается на предприятиях, где каждый день возникает потребность в сканировании и обработке документов больших объемов. Устройство отлично подходит для решения таких задач и позволяет сотрудникам организаций эффективнее справляться со своей работой.
- Все посты
- KVM-оборудование (equipment)
- Powerline-адаптеры
- Безопасность (security)
- Беспроводные адаптеры
- Блоки питания (power supply)
- Видеокарты (videocard)
- Видеонаблюдение (CCTV)
- Диски HDD и твердотельные SSD
- Дисковые полки (JBOD)
- Звуковые карты (sound card)
- Инструменты (instruments)
- Источники бесперебойного питания (ИБП, UPS)
- Кабели и патч-корды
- Коммутаторы (switches)
- Компьютерная периферия (computer peripherals)
- Компьютеры (PC)
- Контроллеры (RAID, HBA, Expander)
- Корпусы для ПК
- Материнские платы для ПК
- Многофункциональные устройства (МФУ)
- Модули памяти для ПК, ноутбуков и серверов
- Мониторы (monitor)
- Моноблоки (All-in-one PC)
- Настольные системы хранения данных (NAS)
- Ноутбуки (notebook, laptop)
- Общая справка
- Охлаждение (cooling)
- Планшеты (tablets)
- Плоттеры (plotter)
- Принтеры (printer)
- Программное обеспечение (software)
- Программное обеспечение для корпоративного потребителя
- Проекторы (projector)
- Процессоры для ПК и серверов
- Рабочие станции (workstation)
- Распределение питания (PDU)
- Расходные материалы для оргтехники
- Расширители Wi-Fi (повторители, репиторы)
- Роутеры (маршрутизаторы)
- Серверы и серверное оборудование
- Сетевые карты (network card)
- Сетевые фильтры (surge protector)
- Сканеры (scanner)
- Телекоммуникационные шкафы и стойки
- Телефония (phone)
- Тонкие клиенты (thin client)
- Трансиверы (trensceiver)
- Умные часы (watch)
Web Crawlers — 10 самых популярных
Бен Итон
Опубликовано 19 августа 2022 г.
Во всемирной паутине есть как плохие, так и хорошие боты. Вы определенно хотите избежать плохих ботов, поскольку они потребляют вашу пропускную способность CDN, занимают ресурсы сервера и крадут ваш контент. С другой стороны, с хорошими ботами (также известными как поисковые роботы) следует обращаться с осторожностью, поскольку они являются важной частью индексации вашего контента поисковыми системами, такими как Google, Bing и Yahoo. В этом сообщении блога мы рассмотрим десятку самых популярных поисковых роботов.
Что такое поисковые роботы?
Веб-сканеры — это компьютерные программы, которые методично и автоматически просматривают Интернет. Их также называют роботами, муравьями или пауками.
Поисковые роботы посещают веб-сайты и читают их страницы и другую информацию, чтобы создать записи для индекса поисковой системы. Основная цель поискового робота — предоставить пользователям полный и актуальный индекс всего доступного онлайн-контента.
Кроме того, поисковые роботы также могут собирать определенные типы информации с веб-сайтов, например контактную информацию или данные о ценах. Используя поисковые роботы, компании могут поддерживать актуальность и эффективность своего присутствия в Интернете (например, SEO, оптимизация внешнего интерфейса и веб-маркетинг).
Используя поисковые роботы, компании могут поддерживать актуальность и эффективность своего присутствия в Интернете (например, SEO, оптимизация внешнего интерфейса и веб-маркетинг).
Поисковые системы, такие как Google, Bing и Yahoo, используют сканеры для правильного индексирования загруженных страниц, чтобы пользователи могли быстрее и эффективнее находить их при поиске. Без поисковых роботов не было бы ничего, что могло бы сказать им, что на вашем сайте есть новый и свежий контент. Карты сайта также могут играть роль в этом процессе. Так что поисковые роботы, по большей части, это хорошо.
Однако иногда возникают проблемы с планированием и загрузкой, поскольку поисковый робот может постоянно опрашивать ваш сайт. И здесь в игру вступает файл robots.txt. Этот файл может помочь контролировать сканирующий трафик и гарантировать, что он не перегрузит ваш сервер.
Веб-сканеры идентифицируют себя для веб-сервера с помощью заголовка запроса User-Agent в HTTP-запросе, и каждый сканер имеет свой уникальный идентификатор. В большинстве случаев вам нужно будет просматривать журналы реферера вашего веб-сервера, чтобы просмотреть трафик поискового робота.
В большинстве случаев вам нужно будет просматривать журналы реферера вашего веб-сервера, чтобы просмотреть трафик поискового робота.
Robots.txt
Поместив файл robots.txt в корень вашего веб-сервера, вы можете определить правила для поисковых роботов, например разрешить или запретить сканирование определенных ресурсов. Поисковые роботы должны следовать правилам, определенным в этом файле. Вы можете применить общие правила ко всем ботам или сделать их более детализированными и указать их конкретные User-Agent строка.
Пример 1
Этот пример предписывает всем роботам поисковых систем не индексировать содержимое веб-сайта. Это определяется путем запрета доступа к корневому каталогу / вашего веб-сайта.
Агент пользователя: * Запретить: /
Пример 2
Этот пример противоположен предыдущему. В этом случае инструкции по-прежнему применяются ко всем пользовательским агентам. Однако в инструкции Disallow ничего не определено, а это означает, что все может быть проиндексировано.
Однако в инструкции Disallow ничего не определено, а это означает, что все может быть проиндексировано.
Агент пользователя: * Запретить:
Чтобы увидеть больше примеров, обязательно ознакомьтесь с нашим подробным сообщением о том, как использовать файл robots.txt.
10 лучших поисковых роботов и поисковых роботов
Существуют сотни поисковых роботов и поисковых роботов, прочесывающих Интернет, но ниже приведен список из 10 популярных поисковых роботов и поисковых роботов, которые мы собрали на основе тех, которые мы регулярно видим в логи нашего веб-сервера.
1. GoogleBot
Являясь крупнейшей в мире поисковой системой, Google использует поисковые роботы для индексации миллиардов страниц в Интернете. Googlebot — это поисковый робот, который Google использует именно для этого.
Googlebot — это два типа поисковых роботов: настольный поисковый робот, который имитирует человека, просматривающего компьютер, и мобильный поисковый робот, который выполняет те же функции, что и iPhone или телефон Android.
Строка пользовательского агента запроса может помочь вам определить подтип Googlebot. Googlebot Desktop и Googlebot Smartphone, скорее всего, будут сканировать ваш веб-сайт. С другой стороны, оба типа сканеров принимают один и тот же токен продукта (токен пользовательского агента) в файле robots.txt. Вы не можете использовать robots.txt для выборочного таргетинга Googlebot Smartphone или Desktop.
Googlebot — очень эффективный поисковый робот, который может быстро и точно индексировать страницы. Однако у него есть некоторые недостатки. Например, робот Googlebot не всегда сканирует все страницы веб-сайта (особенно если веб-сайт большой и сложный).
Кроме того, робот Googlebot не всегда сканирует страницы в режиме реального времени, а это означает, что некоторые страницы могут быть проиндексированы только через несколько дней или недель после их публикации.
Агент пользователя
Googlebot
Полный
User-Agent string
Mozilla/5.0 (совместимый; Googlebot/2.1; +http://www.google.com/bot.html)
Пример робота Googlebot в robots.txt
В этом примере несколько более подробно описаны определенные инструкции. Здесь инструкции относятся только к Googlebot. В частности, он говорит Google не индексировать определенную страницу ( /no-index/your-page.html ).
Агент пользователя: Googlebot Запретить: /no-index/your-page.html
Помимо поискового робота Google, у них на самом деле есть 9additional web crawlers:
| Web crawler | User-Agent string |
|---|---|
| Googlebot News | Googlebot-News |
| Googlebot Images | Googlebot-Image/1.0 |
| Googlebot Видео | Googlebot-Video/1.0 |
| Google Mobile (рекомендуемый телефон) | SAMSUNG-SGH-E250/1.0 Profile/MIDP-2.0 Configuration/CLDC-1.1 UP.Browser/6. 2.3.3.c.1.101 (GUI) ) MMP/2.0 (совместимый; Googlebot-Mobile/2.1; +http://www.google.com/bot.html) 2.3.3.c.1.101 (GUI) ) MMP/2.0 (совместимый; Googlebot-Mobile/2.1; +http://www.google.com/bot.html) |
| Смартфон Google | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (совместимый; Googlebot/2.1; +http://www.google.com/bot.html) |
| Google Mobile Adsense | (совместимо; Mediapartners-Google/2.1; +http://www.google.com/bot.html) |
| Google Adsense | Mediapartners-Google |
| Google AdsBot (качество целевой страницы PPC) | AdsBot-Google (+http://www.google.com/adsbot.html) |
| Поисковый робот Google (получение ресурсов для мобильных устройств) | AdsBot-Google-Mobile-Apps |
Вы можете используйте инструмент Fetch в Google Search Console, чтобы проверить, как Google сканирует или отображает URL-адрес на вашем сайте. Узнайте, может ли робот Googlebot получить доступ к странице на вашем сайте, как он отображает страницу и заблокированы ли какие-либо ресурсы страницы (например, изображения или сценарии) для робота Googlebot.
Вы также можете просмотреть статистику сканирования Googlebot за день, количество загруженных килобайт и время, затраченное на загрузку страницы.
См. документацию robots.txt для робота Google.
2. Bingbot
Bingbot — это поисковый робот, развернутый Microsoft в 2010 году для предоставления информации их поисковой системе Bing. Это замена того, что раньше было ботом MSN.
Агент пользователя
Bingbot
Полный
User-Agent string
Mozilla/5.0 (совместимый; Bingbot/2.0; +http://www.bing.com/bingbot.htm)
У Bing также есть очень похожий на Google инструмент, называемый Fetch as Bingbot, в Инструментах для веб-мастеров Bing. Fetch As Bingbot позволяет запросить сканирование страницы и показать ее вам так, как ее увидит наш сканер. Вы увидите код страницы так, как его увидит Bingbot, что поможет вам понять, видят ли они вашу страницу так, как вы предполагали.
См. документацию Bingbot robots. txt.
txt.
3. Slurp Bot
Результаты поиска Yahoo поступают от поискового робота Yahoo Slurp и поискового робота Bing, так как многие Yahoo работают на базе Bing. Сайты должны разрешать доступ Yahoo Slurp, чтобы они отображались в результатах поиска Yahoo Mobile.
Кроме того, Slurp делает следующее:
- Собирает контент с партнерских сайтов для включения в такие сайты, как Yahoo News, Yahoo Finance и Yahoo Sports.
- Доступ к страницам сайтов в Интернете для подтверждения точности и улучшения персонализированного контента Yahoo для наших пользователей.
Агент пользователя
Slurp
Полный
User-Agent string
Mozilla/5.0 (совместимый; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp)
См. документацию Slurp robots.txt.
4. DuckDuckBot
DuckDuckBot — это веб-сканер для DuckDuckGo, поисковой системы, которая стала довольно популярной, поскольку известна своей конфиденциальностью и отсутствием слежки за вами. Теперь он обрабатывает более 93 миллионов запросов в день. DuckDuckGo получает результаты из разных источников. К ним относятся сотни вертикальных источников, предоставляющих нишевые мгновенные ответы, DuckDuckBot (их поисковый робот) и краудсорсинговые сайты (Википедия). У них также есть более традиционные ссылки в результатах поиска, которые они получают от Yahoo! и Бинг.
Теперь он обрабатывает более 93 миллионов запросов в день. DuckDuckGo получает результаты из разных источников. К ним относятся сотни вертикальных источников, предоставляющих нишевые мгновенные ответы, DuckDuckBot (их поисковый робот) и краудсорсинговые сайты (Википедия). У них также есть более традиционные ссылки в результатах поиска, которые они получают от Yahoo! и Бинг.
Агент пользователя
DuckDuckBot
Полный
User-Agent string
DuckDuckBot/1.0; (+http://duckduckgo.com/duckduckbot.html)
It respects WWW::RobotRules and originates from these IP addresses:
- 72.94.249.34
- 72.94.249.35
- 72.94.249.36
- 72.94.249.37
- 72.94.249.38
5. Baiduspider
Baiduspider — это официальное название паука китайской поисковой системы Baidu. Он сканирует веб-страницы и возвращает обновления в индекс Baidu. Baidu — ведущая китайская поисковая система, на долю которой приходится 80% всего рынка поисковых систем материкового Китая.
Агент пользователя
Baiduspider
Full
User-Agent string
Mozilla/5.0 (совместимо; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
Besides Baidu’s web search crawler, they actually have 6 additional web crawlers:
| Web crawler | User-Agent string |
|---|---|
| Image Search | Baiduspider-image |
| Video Search | Baiduspider-video |
| News Search | Baiduspider-news |
| Baidu wishlists | Baiduspider-favo |
| Baidu Union | Baiduspider-cpro |
| Business Search | Baiduspider -ads |
| Другие страницы поиска | Baiduspider |
См. документацию Baidu robots.txt.
6. Яндекс Бот
ЯндексБот — поисковый робот для одной из крупнейших российских поисковых систем Яндекс.
User-Agent
ЯндексБот
Full
User-Agent string
Mozilla/5.0 (совместимо; YandexBot/3.0; +http://yandex.com/bots)
Существует множество различных строк User-Agent, которые ЯндексБот может отображать в логах вашего сервера. См. полный список роботов Яндекса и документацию Яндекса robots.txt.
7. Паук Согоу
Sogou Spider — это поисковый робот для Sogou.com, ведущей китайской поисковой системы, которая была запущена в 2004 году.
Примечание. чрезмерное ползание.
User-Agent
Sogou Pic Spider/3.0 (http://www.sogou.com/docs/help/webmasters.htm#07) Головной паук Sogou/3.0 (http://www.sogou.com/docs/help/webmasters.htm#07) Веб-паук Sogou/4.0 (+http://www.sogou.com/docs/help/webmasters.htm#07) Паук Sogou Orion/3.0 (http://www.sogou.com/docs/help/webmasters.htm#07) Sogou-Test-Spider/4.0 (совместимый; MSIE 5.5; Windows 98)
8. Exabot
Exabot — поисковый робот для Exalead, поисковой системы, базирующейся во Франции. Он был основан в 2000 году и имеет более 16 миллиардов проиндексированных страниц.
Он был основан в 2000 году и имеет более 16 миллиардов проиндексированных страниц.
User-Agent
Mozilla/5.0 (совместимый; Konqueror/3.5; Linux) KHTML/3.5.5 (как Gecko) (Exabot-Thumbnails) Mozilla/5.0 (совместимо; Exabot/3.0; +http://www.exabot.com/go/robot)
См. документацию Exabot robots.txt.
9. Facebook external hit
Facebook позволяет своим пользователям отправлять ссылки на интересный веб-контент другим пользователям Facebook. Часть того, как это работает в системе Facebook, включает временное отображение определенных изображений или деталей, связанных с веб-контентом, таких как название веб-страницы или встроенный тег видео. Система Facebook извлекает эту информацию только после того, как пользователь предоставит ссылку.
Одним из их основных сканирующих ботов является Facebot, предназначенный для повышения эффективности рекламы.
User-Agent
фейсбот facebookexternalhit/1.0 (+http://www.facebook.com/externalhit_uatext.php) facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)
См. документацию Facebot robots.txt.
10. Applebot
Бренд компьютерных технологий Apple использует поисковый робот Applebot, в частности Siri и Spotlight Suggestions, для предоставления персонализированных услуг своим пользователям.
Агент пользователя
Applebot
Full
User-Agent string
Mozilla/5.0 (Device; OS_version) AppleWebKit/WebKit_version (KHTML, как Gecko) Версия/Safari_версия Safari/WebKit_версия (Applebot/Applebot_version)
Другие популярные поисковые роботы
Apache Nutch
Apache Nutch — поисковый робот с открытым исходным кодом, написанный на Java. Он выпущен под лицензией Apache и управляется Apache Software Foundation.
Nutch может работать на одной машине, но чаще используется в распределенной среде. На самом деле, Nutch был разработан с нуля, чтобы быть масштабируемым и легко расширяемым.
Орех очень гибкий и может использоваться для различных целей. Например, Nutch можно использовать для обхода всего Интернета или только определенных веб-сайтов. Кроме того, Nutch можно настроить на индексацию страниц в режиме реального времени или по расписанию.
Одним из основных преимуществ Apache Nutch является его масштабируемость. Nutch можно легко масштабировать для обработки больших объемов данных и трафика. Например, большой веб-сайт электронной коммерции может использовать Apache Nutch для сканирования и индексации своего каталога продуктов. Это позволит клиентам искать продукты на своем веб-сайте с помощью внутренней поисковой системы компании.
Кроме того, Apache Nutch можно использовать для сбора данных о веб-сайтах. Компании могут использовать Apache Nutch для сканирования веб-сайтов конкурентов и сбора информации об их продуктах, ценах и контактной информации. Затем эта информация может быть использована для улучшения их присутствия в Интернете.
Однако у Apache Nutch есть некоторые недостатки. Например, это может быть сложно настроить и использовать. Кроме того, Apache Nutch не так широко используется, как другие поисковые роботы, а это означает, что для него доступна меньшая поддержка.
Например, это может быть сложно настроить и использовать. Кроме того, Apache Nutch не так широко используется, как другие поисковые роботы, а это означает, что для него доступна меньшая поддержка.
Screaming Frog
Screaming Frog SEO Spider — это настольная программа (ПК или Mac), которая сканирует ссылки, изображения, CSS, скрипты и приложения веб-сайтов с точки зрения SEO.
Он извлекает ключевые элементы сайта для SEO, представляет их на вкладках по типам и позволяет вам фильтровать общие проблемы SEO или нарезать данные так, как вам нравится, экспортируя их в Excel.
Вы можете просматривать, анализировать и фильтровать данные сканирования по мере их сбора и извлечения в режиме реального времени с помощью простого интерфейса.
Программа бесплатна для небольших сайтов (до 500 URL). Для больших сайтов требуется лицензия.
Screaming Frog использует Chromium WRS для сканирования динамических веб-сайтов с большим количеством JavaScript, таких как Angular, React и Vue. js. Создание карты сайта WordPress, извлечение XPath и визуализация архитектуры сайта — другие важные функции.
js. Создание карты сайта WordPress, извлечение XPath и визуализация архитектуры сайта — другие важные функции.
Платформа обслуживает такие корпорации, как Apple, Amazon, Disney и даже Google. Screaming Frog также является популярным инструментом среди владельцев агентств и SEO-специалистов, которые управляют SEO для нескольких клиентов.
Deepcrawl
Deepcrawl — это облачный поисковый робот, который позволяет пользователям сканировать веб-сайты и собирать данные об их структуре, содержании и производительности.
DeepCrawl предоставляет пользователям несколько функций и опций, включая возможность сканирования веб-сайтов на основе JavaScript, настройку процесса сканирования и создание подробных отчетов.
Одной из самых уникальных функций Deepcrawl является его способность сканировать веб-сайты, созданные с помощью JavaScript. Это возможно, потому что Deepcrawl использует безголовый браузер (например, Chrome) для отображения содержимого веб-сайта перед его сканированием.
Это означает, что Deepcrawl может сканировать и собирать данные о веб-сайтах, которые не всегда могут быть доступны другим поисковым роботам.
Помимо гибких API, данные Deepcrawl интегрируются с Google Analytics, Google Search Console и другими популярными инструментами. Это позволяет пользователям легко сравнивать данные своего веб-сайта с данными конкурентов. Это также позволяет им связывать бизнес-данные (например, данные о продажах) с данными своего веб-сайта, чтобы получить полное представление о том, как работает их веб-сайт.
Deepcrawl лучше всего подходит для компаний с большими веб-сайтами с большим количеством контента и страниц. Платформа менее подходит для небольших веб-сайтов или тех, которые не меняются очень часто.
Deepcrawl предлагает три различных продукта:
- Automation Hub: этот продукт интегрируется с конвейером CI/CD и автоматически сканирует ваш веб-сайт с более чем 200 правилами тестирования SEO QA.
- Центр аналитики: этот продукт позволяет вам получать полезную информацию из данных вашего веб-сайта и улучшать SEO вашего веб-сайта.

- Концентратор мониторинга: этот продукт отслеживает изменения на вашем веб-сайте и уведомляет вас о появлении новых проблем.
Предприятия используют эти три продукта для улучшения SEO своего веб-сайта, отслеживания изменений и сотрудничества с командами разработчиков.
Octoparse
Octoparse — это удобное клиентское программное обеспечение для сканирования веб-страниц, которое позволяет извлекать данные со всего Интернета. Программа специально разработана для людей, не являющихся программистами, и имеет простой интерфейс «укажи и щелкни».
С Octoparse вы можете запускать запланированные облачные извлечения для извлечения динамических данных, создавать рабочие процессы для автоматического извлечения данных с веб-сайтов и использовать его API парсинга веб-страниц для доступа к данным.
Его прокси-серверы IP позволяют сканировать веб-сайты без блокировки, а встроенная функция Regex автоматически очищает данные.
Благодаря готовым шаблонам скрейпера вы можете начать извлекать данные с популярных веб-сайтов, таких как Yelp, Google Maps, Facebook и Amazon, за считанные минуты. Вы также можете создать свой собственный парсер, если его нет в наличии для ваших целевых веб-сайтов.
Вы также можете создать свой собственный парсер, если его нет в наличии для ваших целевых веб-сайтов.
HTTrack
Вы можете использовать бесплатное ПО HTTrack для загрузки целых сайтов на свой компьютер. Благодаря поддержке Windows, Linux и других систем Unix этот инструмент с открытым исходным кодом может использоваться миллионами.
Средство копирования веб-сайтов HTTrack позволяет загружать веб-сайты на компьютер, чтобы вы могли просматривать их в автономном режиме. Программу также можно использовать для зеркалирования веб-сайтов, что означает, что вы можете создать точную копию веб-сайта на своем сервере.
Программа проста в использовании и имеет множество функций, в том числе возможность возобновлять прерванные загрузки, обновлять существующие веб-сайты и создавать статические копии динамических веб-сайтов.
Вы можете получить файлы, фотографии и HTML-код с зеркального веб-сайта и возобновить прерванную загрузку.
Хотя HTTrack можно использовать для загрузки веб-сайтов любого типа, он особенно полезен для загрузки веб-сайтов, которые больше не доступны в сети.
HTTrack — отличный инструмент для тех, кто хочет загрузить весь веб-сайт или создать его зеркальную копию. Однако следует отметить, что программу можно использовать для загрузки нелегальных копий веб-сайтов.
Таким образом, вы должны использовать HTTrack только в том случае, если у вас есть разрешение от владельца веб-сайта.
SiteSucker
SiteSucker — это приложение для macOS, которое загружает веб-сайты. Он асинхронно копирует веб-страницы сайта, изображения, PDF-файлы, таблицы стилей и другие файлы на ваш локальный жесткий диск, дублируя структуру каталогов сайта.
Вы также можете использовать SiteSucker для загрузки определенных файлов с веб-сайтов, таких как файлы MP3.
Программа может использоваться для создания локальных копий веб-сайтов, что делает ее идеальной для просмотра в автономном режиме.
Это также полезно для загрузки целых сайтов, чтобы вы могли просматривать их на своем компьютере без подключения к Интернету.
Одним из недостатков SiteSucker является то, что он не может обрабатывать Javascript (хотя может обрабатывать Flash). Тем не менее, он по-прежнему полезен для загрузки веб-сайтов на ваш Mac.
Тем не менее, он по-прежнему полезен для загрузки веб-сайтов на ваш Mac.
Webz.io
Пользователи могут использовать веб-приложение Webz.io для получения данных в режиме реального времени путем сканирования онлайн-источников по всему миру в различных удобных форматах. Этот поисковый робот позволяет сканировать данные и извлекать ключевые слова на нескольких языках на основе многочисленных критериев из различных источников.
Архив позволяет пользователям получать доступ к историческим данным. Пользователи могут легко индексировать и искать структурированные данные, просканированные Webhose, используя его интуитивно понятный интерфейс/API. Вы можете сохранять очищенные данные в форматах JSON, XML и RSS. Кроме того, Webz.io поддерживает до 80 языков с результатами сканирования данных.
Freemium бизнес-модель Webz.io должна подойти для предприятий с базовыми требованиями к сканированию. Для предприятий, которым требуется более надежное решение, Webz.io также предлагает поддержку мониторинга СМИ, угроз кибербезопасности, анализа рисков, финансового анализа, веб-аналитики и защиты от кражи личных данных.
Они даже поддерживают решения API даркнета для бизнес-аналитики.
UiPath
UiPath — это приложение Windows, которое можно использовать для автоматизации повторяющихся задач. Это полезно для парсинга веб-страниц, поскольку оно может автоматически извлекать данные с веб-сайтов.
Программа проста в использовании и не требует знаний в области программирования. Он имеет визуальный интерфейс перетаскивания, который упрощает создание сценариев автоматизации.
С помощью UiPath вы можете извлекать табличные данные и данные на основе шаблонов с веб-сайтов, PDF-файлов и других источников. Программу также можно использовать для автоматизации таких задач, как заполнение онлайн-форм и загрузка файлов.
Коммерческая версия инструмента предоставляет дополнительные возможности сканирования. При работе со сложными пользовательскими интерфейсами этот подход очень успешен. Инструмент очистки экрана может извлекать данные из таблиц как по отдельным словам, так и по группам текста, а также по блокам текста, таким как RSS-каналы.
Кроме того, вам не нужны навыки программирования для создания интеллектуальных веб-агентов, но если вы хакер .NET, вы сможете полностью контролировать их данные.
Плохие боты
Хотя большинство поисковых роботов безопасны, некоторые из них могут использоваться в злонамеренных целях. Эти вредоносные веб-сканеры, или «боты», могут использоваться для кражи информации, проведения атак и совершения мошенничества. Также все чаще обнаруживается, что эти боты игнорируют директивы robots.txt и переходят непосредственно к сканированию веб-сайтов.
Some prominent bad bots are as listed below:
- PetalBot
- SEMrushBot
- Majestic
- DotBot
- AhrefsBot
Protecting your site from malicious web crawlers
To protect your website from bad bots, you can use брандмауэр веб-приложений (WAF) для защиты вашего сайта от ботов и других угроз. WAF — это часть программного обеспечения, которое находится между вашим веб-сайтом и Интернетом и фильтрует трафик до того, как он попадет на ваш сайт.
CDN также может помочь защитить ваш сайт от ботов. CDN — это сеть серверов, которые доставляют контент пользователям в зависимости от их географического положения.
Когда пользователь запрашивает страницу с вашего веб-сайта, CDN направляет запрос на сервер, ближайший к местоположению пользователя. Это может помочь снизить риск атаки ботов на ваш сайт, поскольку им придется нацеливаться на каждый сервер CDN в отдельности.
У KeyCDN есть отличная функция, которую вы можете включить на своей панели инструментов, которая называется «Блокировка плохих ботов». KeyCDN использует полный список известных вредоносных ботов и блокирует их на основе их User-Agent строка.
При добавлении новой зоны для функции Блокировать плохих ботов устанавливается значение отключено . Этот параметр можно установить на с включенным вместо этого, если вы хотите, чтобы плохие боты автоматически блокировались.
Ресурсы бота
Возможно, вы видите в своих журналах некоторые строки пользовательского агента, которые вас беспокоят. У Кайо Алмейды также есть неплохой список в его проекте GitHub для поисковых агентов.
У Кайо Алмейды также есть неплохой список в его проекте GitHub для поисковых агентов.
Резюме
Существуют сотни различных поисковых роботов, но, надеюсь, вы уже знакомы с несколькими наиболее популярными из них. Опять же, вы должны быть осторожны при блокировании любого из них, так как они могут вызвать проблемы с индексацией. Всегда полезно проверить журналы вашего веб-сервера, чтобы узнать, как часто они сканируют ваш сайт.
Какой ваш любимый поисковый робот? Дайте нам знать в комментариях ниже.
Что такое веб-краулер? (И как это работает)
Поисковые системы являются воротами легкодоступной информации, но поисковые роботы, их малоизвестные помощники, играют решающую роль в сборе онлайн-контента. Кроме того, они необходимы для вашей стратегии поисковой оптимизации (SEO).
Что такое поисковый робот?
Веб-сканер , также называемый ботом поисковой системы или веб-пауком, представляет собой цифровой бот, который сканирует всемирную паутину, чтобы найти и индексировать страницы для поисковых систем.
Поисковые системы волшебным образом не знают, какие веб-сайты существуют в Интернете. Программы должны сканировать и индексировать их, прежде чем они смогут предоставить нужные страницы по ключевым словам и фразам или словам, которые люди используют для поиска полезной страницы.
Думайте об этом как о покупке продуктов в новом магазине.
Вы должны пройтись по проходам и посмотреть на товары, прежде чем сможете выбрать то, что вам нужно.
Таким же образом поисковые системы используют поисковые роботы в качестве помощников для поиска страниц в Интернете, прежде чем сохранять данные этих страниц для использования в будущих поисках.
Эта аналогия также применима к тому, как поисковые роботы перемещаются от ссылки к ссылке на странице.
Вы не можете увидеть, что находится за банкой супа на полке продуктового магазина, пока не поднимете банку впереди.
Сканеры поисковых систем также нуждаются в отправной точке — ссылке — прежде чем они смогут найти следующую страницу и следующую ссылку.
Как работает поисковый робот?
Поисковые системы сканируют или посещают сайты, переходя между ссылками на страницах. Однако если у вас есть новый веб-сайт без ссылок, соединяющих ваши страницы с другими, вы можете попросить поисковые системы выполнить сканирование веб-сайта , отправив свой URL-адрес в Google Search Console.
В нашем видео вы можете узнать больше о том, как проверить, доступен ли ваш сайт для сканирования и индексации!
Краулеры действуют как исследователи в новой земле.
Они всегда ищут ссылки на страницах, которые можно обнаружить, и записывают их на карту, как только понимают их особенности. Но сканеры веб-сайтов могут просматривать только общедоступные страницы на веб-сайтах, а частные страницы, которые они не могут сканировать, помечаются как «темная сеть».
Поисковые роботы, пока они находятся на странице, собирают информацию о странице, например копию и метатеги. Затем поисковые роботы сохраняют страницы в индексе, чтобы алгоритм Google мог сортировать их по содержащимся в них словам, чтобы позже получить их и ранжировать для пользователей.
Затем поисковые роботы сохраняют страницы в индексе, чтобы алгоритм Google мог сортировать их по содержащимся в них словам, чтобы позже получить их и ранжировать для пользователей.
Какие примеры поисковых роботов можно привести?
Итак, какие есть примеры поисковых роботов?
У всех популярных поисковых систем есть поисковые роботы, а у крупных — несколько поисковых роботов с конкретными задачами.
Например, у Google есть основной поисковый робот Googlebot, который выполняет сканирование мобильных и настольных компьютеров.
Но есть также несколько дополнительных ботов для Google , , таких как Googlebot Images, Googlebot Videos, Googlebot News и AdsBot.
Вот несколько других поисковых роботов, с которыми вы можете столкнуться:
- DuckDuckBot для DuckDuckGo
- Яндекс Бот для Яндекса
- Baiduspider для Baidu
- Yahoo! Хлеб для Yahoo!
В Bing также есть стандартный поисковый робот Bingbot и более специализированные боты, такие как MSNBot-Media и BingPreview. Его основным сканером раньше был MSNBot, который с тех пор отошел на второй план для стандартного сканирования и теперь выполняет только второстепенные задачи сканирования веб-сайтов.
Его основным сканером раньше был MSNBot, который с тех пор отошел на второй план для стандартного сканирования и теперь выполняет только второстепенные задачи сканирования веб-сайтов.
Почему поисковые роботы важны для поисковой оптимизации
Поисковая оптимизация — улучшение вашего сайта для повышения рейтинга — требует, чтобы страницы были доступны и читабельными для поисковых роботов.
Сканирование — это первый способ, с помощью которого поисковые системы захватывают ваши страницы, но регулярное сканирование помогает им отображать внесенные вами изменения и быть в курсе актуальности вашего контента. Поскольку сканирование выходит за рамки начала вашей SEO-кампании, вы можете рассматривать поведение поискового робота как упреждающую меру, которая поможет вам появиться в результатах поиска и улучшить взаимодействие с пользователем.
Продолжайте читать, чтобы узнать о взаимосвязи между поисковыми роботами и поисковой оптимизацией.
Управление бюджетом сканирования
Непрерывное сканирование веб-страниц дает вашим недавно опубликованным страницам шанс появиться на страницах результатов поисковой системы (SERP). Однако вам не предоставляется неограниченное сканирование из Google и большинства других поисковых систем.
Однако вам не предоставляется неограниченное сканирование из Google и большинства других поисковых систем.
У Google есть краулинговый бюджет, который направляет своих ботов:
- Как часто сканировать
- Какие страницы сканировать
- Допустимая нагрузка на сервер
Хорошо, что есть краулинговый бюджет.
В противном случае активность поисковых роботов и посетителей может привести к перегрузке вашего сайта.
Если вы хотите, чтобы ваш сайт работал бесперебойно, вы можете настроить сканирование веб-страниц с помощью ограничения скорости сканирования и потребности в сканировании.
Ограничение скорости сканирования отслеживает выборку на сайтах, чтобы скорость загрузки не страдала и не приводила к всплеску ошибок. Вы можете изменить его в Google Search Console, если у вас возникли проблемы с Googlebot.
Спрос на сканирование — это уровень интереса Google и его пользователей к вашему веб-сайту. Итак, если у вас еще нет широкой аудитории, робот Googlebot не будет сканировать ваш сайт так часто, как очень популярные.
Препятствия для поисковых роботов
Существует несколько способов целенаправленно заблокировать поисковым роботам доступ к вашим страницам.
Не каждая страница на вашем сайте должна ранжироваться в поисковой выдаче, и эти блокираторы поисковых роботов могут защитить конфиденциальные, избыточные или нерелевантные страницы от появления по ключевым словам.
Первым препятствием является метатег noindex , который не позволяет поисковым системам индексировать и ранжировать определенную страницу. Обычно разумно применять noindex к страницам администратора, страницам благодарности и результатам внутреннего поиска.
Еще одним препятствием для сканера является файл robots.txt . Эта директива не является окончательной, потому что поисковые роботы могут отказаться подчиняться вашим файлам robots.txt, но она удобна для контроля вашего краулингового бюджета.
Оптимизация сканирования веб-сайтов поисковыми системами с помощью WebFX
Изучив основы сканирования, вы должны получить ответ на свой вопрос: «Что такое веб-сканер?» Сканеры поисковых систем — невероятные инструменты для поиска и записи страниц веб-сайтов.
 5 мм)
5 мм) 0Ah (0615990M41)
0Ah (0615990M41) 0 Ah + ЗУ (0615990M41)
0 Ah + ЗУ (0615990M41) 99 M
99 M 8 мм
8 мм 99 M
99 M Торцовочная пила с двойным скосом
Торцовочная пила с двойным скосом доступ к передним элементам управления
доступ к передним элементам управления Нижний молдинг против забора
Нижний молдинг против забора х 13-1/2 дюйма. (2×14 размерных пиломатериалов)
х 13-1/2 дюйма. (2×14 размерных пиломатериалов) (Адаптер VAC002 несовместим с GCM12SD.)
(Адаптер VAC002 несовместим с GCM12SD.) Торцовочная пила с двойным скосом, (1) Premium 12 дюймов. Лезвие с твердосплавным наконечником на 60 зубьев, (1) гаечный ключ, (1) безынструментальный вертикальный рабочий зажим, (1) мешок для сбора пыли в сборе, (1) колено вакуумного адаптера
Торцовочная пила с двойным скосом, (1) Premium 12 дюймов. Лезвие с твердосплавным наконечником на 60 зубьев, (1) гаечный ключ, (1) безынструментальный вертикальный рабочий зажим, (1) мешок для сбора пыли в сборе, (1) колено вакуумного адаптера Лезвие с твердосплавным наконечником, 24 зубца, (1) зажим для материала, (1) гаечный ключ, (1) мешок для пыли
Лезвие с твердосплавным наконечником, 24 зубца, (1) зажим для материала, (1) гаечный ключ, (1) мешок для пыли
 8-1 SCM 2GDC
8-1 SCM 2GDC
 руRAWLPLUGLigansФЭСТКитайRUBIFROSTМагнитогорский электронный заводНовосибирский Респираторный ЗаводSilaРемонт на 100%ПУШКИНОMasterFlowПромышленникФиксарЭРАSAMWELDEVRENSait DemirciMr. ЭКОНОМИКПРАКТИКАRICHBOSSONGOBOelementaTekafixTERMOCLIPAkfix
руRAWLPLUGLigansФЭСТКитайRUBIFROSTМагнитогорский электронный заводНовосибирский Респираторный ЗаводSilaРемонт на 100%ПУШКИНОMasterFlowПромышленникФиксарЭРАSAMWELDEVRENSait DemirciMr. ЭКОНОМИКПРАКТИКАRICHBOSSONGOBOelementaTekafixTERMOCLIPAkfix





 двусторонняя кувалда с рукояткой из орехового дерева.
двусторонняя кувалда с рукояткой из орехового дерева.


 Длина головки 6 3/4 дюйма. Длина инструмента 15 дюймов. Что вы делаете с собачьей мордой? . Ими можно рисовать сталь, но это неудобно. За этим стоит техника, но это сложно и…
Длина головки 6 3/4 дюйма. Длина инструмента 15 дюймов. Что вы делаете с собачьей мордой? . Ими можно рисовать сталь, но это неудобно. За этим стоит техника, но это сложно и… Диаметр передней части 3,3 дюйма. Длина головки 5,25 дюйма.
Диаметр передней части 3,3 дюйма. Длина головки 5,25 дюйма.




 ..
..




 Они оснащены вентилятором, который при включении создаёт воздушный поток, позволяющий самой конструкции не касаться земли. Это обеспечивает хорошую манёвренность, особенно для труднодоступных участков.
Они оснащены вентилятором, который при включении создаёт воздушный поток, позволяющий самой конструкции не касаться земли. Это обеспечивает хорошую манёвренность, особенно для труднодоступных участков. Недорогие модели сделаны из пластика. Самым лучшим вариантом будет приобрести устройство с металлическим корпусом.
Недорогие модели сделаны из пластика. Самым лучшим вариантом будет приобрести устройство с металлическим корпусом. Хотя оборудование фирмы не отличается огромным функционалом, но обеспечивает максимальную надёжность. Так, данная модель является самой долговечной среди аналогов, так как способна работать долго без специального обслуживания. Корпус является стальным, что обеспечивает его прочность. Высота скоса пятиступенчатая.
Хотя оборудование фирмы не отличается огромным функционалом, но обеспечивает максимальную надёжность. Так, данная модель является самой долговечной среди аналогов, так как способна работать долго без специального обслуживания. Корпус является стальным, что обеспечивает его прочность. Высота скоса пятиступенчатая. При работе с электрическими моделями в первую очередь стоит проверить исправность шнура.
При работе с электрическими моделями в первую очередь стоит проверить исправность шнура. При длительном хранении (от 3 месяцев) производят консервацию деталей, которые не имеют лакового покрытия.
При длительном хранении (от 3 месяцев) производят консервацию деталей, которые не имеют лакового покрытия. Высокая маневренность, современный дизайн, простота работы и практически полная необслуживаемость — явные преимущества изделия ЗУБР
Высокая маневренность, современный дизайн, простота работы и практически полная необслуживаемость — явные преимущества изделия ЗУБР Катушка косилки должна иметь от трех до семи лезвий, в зависимости от типа модели.
Катушка косилки должна иметь от трех до семи лезвий, в зависимости от типа модели. Роторные косилки обычно приводятся в действие бензиновыми двигателями или электрическими двигателями.
Роторные косилки обычно приводятся в действие бензиновыми двигателями или электрическими двигателями. Этот термин означает либо компостирование, либо мульчирование обрезков там, где они производятся.
Этот термин означает либо компостирование, либо мульчирование обрезков там, где они производятся. паттинг-грин
паттинг-грин Часто задаваемые вопросы: В чем разница между двумя вариантами? Какая косилка лучше всего подходит для моего газона? Какой вариант дешевле? В этом блоге рассматриваются различия между каждым типом косилки, а также различные факторы, которые домовладелец может учитывать при совершении этой покупки.
Часто задаваемые вопросы: В чем разница между двумя вариантами? Какая косилка лучше всего подходит для моего газона? Какой вариант дешевле? В этом блоге рассматриваются различия между каждым типом косилки, а также различные факторы, которые домовладелец может учитывать при совершении этой покупки. Основное различие между катушкой и роторной газонокосилкой заключается в режущем механизме. Ножи барабанных косилок вращаются с помощью горизонтального вала. Лопасти вращаются на центральной оси, которая заставляет катушку вращаться. Лезвия также создают восходящий поток, который поднимает траву, чтобы ее можно было косить. С другой стороны, роторные косилки срезают за счет высокоскоростного удара, похожего на удар мачете, который «ударяет» по травинкам, как крыло вертолета. Они режут в горизонтальном положении, приводимом в движение небольшим двигателем. По этой причине барабанные косилки имеют лучшее качество среза. На рисунках ниже показано, как работают различные косилки и как выглядят их ножи:
Основное различие между катушкой и роторной газонокосилкой заключается в режущем механизме. Ножи барабанных косилок вращаются с помощью горизонтального вала. Лопасти вращаются на центральной оси, которая заставляет катушку вращаться. Лезвия также создают восходящий поток, который поднимает траву, чтобы ее можно было косить. С другой стороны, роторные косилки срезают за счет высокоскоростного удара, похожего на удар мачете, который «ударяет» по травинкам, как крыло вертолета. Они режут в горизонтальном положении, приводимом в движение небольшим двигателем. По этой причине барабанные косилки имеют лучшее качество среза. На рисунках ниже показано, как работают различные косилки и как выглядят их ножи: Барабанные косилки более эффективны, когда трава не слишком длинная, влажная или волнистая. Катушечным косилкам также трудно измельчать ветки и преодолевать камни. Как и следовало ожидать, барабанные косилки обычно используются для более низкой высоты скашивания, необходимой для спортивных площадок или полей для гольфа, которые обычно косят несколько раз в неделю. Для домовладельцев барабанные косилки лучше всего подходят для трав теплого сезона, таких как святой августин, зойзия и бермудская трава, из-за грубой текстуры сортов, облегчающей стрижку. 9№ 0017
Барабанные косилки более эффективны, когда трава не слишком длинная, влажная или волнистая. Катушечным косилкам также трудно измельчать ветки и преодолевать камни. Как и следовало ожидать, барабанные косилки обычно используются для более низкой высоты скашивания, необходимой для спортивных площадок или полей для гольфа, которые обычно косят несколько раз в неделю. Для домовладельцев барабанные косилки лучше всего подходят для трав теплого сезона, таких как святой августин, зойзия и бермудская трава, из-за грубой текстуры сортов, облегчающей стрижку. 9№ 0017 Пренебрежение заточкой лезвий на барабанной косилке приведет к неэффективному скашиванию травы, возможно, повреждению травы и повышению ее восприимчивости к болезням. Хотя роторные ножи легче затачивать, чем ножи барабанных косилок, газонокосилки требуют такого же ежегодного обслуживания, как и бензиновые роторные косилки (замена масла, замена воздушного фильтра и замена свечей зажигания).
Пренебрежение заточкой лезвий на барабанной косилке приведет к неэффективному скашиванию травы, возможно, повреждению травы и повышению ее восприимчивости к болезням. Хотя роторные ножи легче затачивать, чем ножи барабанных косилок, газонокосилки требуют такого же ежегодного обслуживания, как и бензиновые роторные косилки (замена масла, замена воздушного фильтра и замена свечей зажигания).

 Ищите ювелирный дом «Минсин» на карте города. Более точное место указано на скриншотах ниже. На месте вы найдете управляющую лавкой девушку по имени Син Си.
Ищите ювелирный дом «Минсин» на карте города. Более точное место указано на скриншотах ниже. На месте вы найдете управляющую лавкой девушку по имени Син Си.
 При повышении уровня статуи вы будете получать некоторое количество Анемо печатей.
При повышении уровня статуи вы будете получать некоторое количество Анемо печатей. За них можно купить материалы для вознесения героев, заготовки для крафта оружия и многое другое. В этом гайде мы расскажем, где найти сувенирные лавки, как получить печати стихий в Genshin Impact и на что конкретно их можно потратить.
За них можно купить материалы для вознесения героев, заготовки для крафта оружия и многое другое. В этом гайде мы расскажем, где найти сувенирные лавки, как получить печати стихий в Genshin Impact и на что конкретно их можно потратить. Ее владелицу зовут Син Си. На скриншоте ниже вы можете увидеть точное местоположение НПС.
Ее владелицу зовут Син Си. На скриншоте ниже вы можете увидеть точное местоположение НПС. За каждый уровень статуи игрок получает в награду 5-15 печатей Анемо. Количество печатей зависит от уровня статуи.
За каждый уровень статуи игрок получает в награду 5-15 печатей Анемо. Количество печатей зависит от уровня статуи.
 Только когда святыня достигнет 50 уровня, вы сможете тратить заработанные печати на покупку товаров у Микоси Гэнитиро в столице региона.
Только когда святыня достигнет 50 уровня, вы сможете тратить заработанные печати на покупку товаров у Микоси Гэнитиро в столице региона. То есть, если вы выкупите какой-либо товар, то больше приобрести его не сможете. Это касается всего, кроме моры. Бесконечная покупка данной валюты разблокируется после того, как игрок выкупит абсолютно все товары у владельца сувенирной лавки.
То есть, если вы выкупите какой-либо товар, то больше приобрести его не сможете. Это касается всего, кроме моры. Бесконечная покупка данной валюты разблокируется после того, как игрок выкупит абсолютно все товары у владельца сувенирной лавки.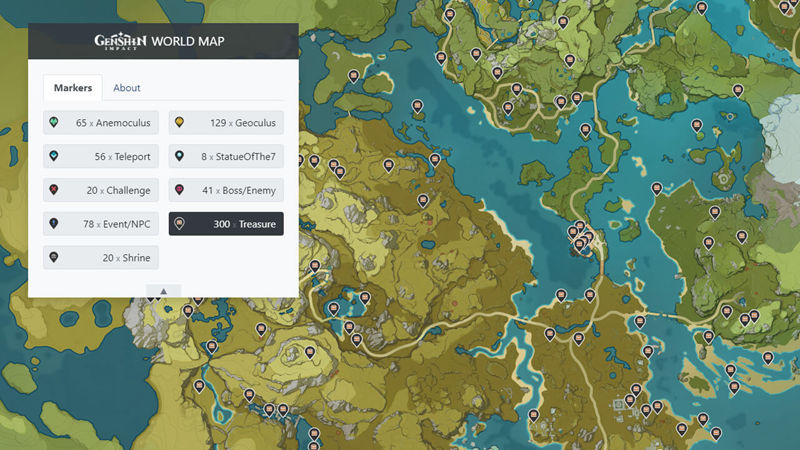 Загляните к нам позже.
Загляните к нам позже. Плагин Regular Labs Library не установлен.
Плагин Regular Labs Library не установлен. ..
.. .. и SunDance удовлетворила эти потребности, а затем и некоторые другие! На самом деле не так много большего, о чем мы могли бы просить.
.. и SunDance удовлетворила эти потребности, а затем и некоторые другие! На самом деле не так много большего, о чем мы могли бы просить.  ..SunDance сыграл ключевую роль в успехе нашего ежемесячного полноцветного общественного журнала. С SunDance приятно работать. Они намного превзошли наши ожидания в отношении качества продукции, соблюдения сроков и обслуживания клиентов. Я бы дал им 6 звезд, если бы мог!
..SunDance сыграл ключевую роль в успехе нашего ежемесячного полноцветного общественного журнала. С SunDance приятно работать. Они намного превзошли наши ожидания в отношении качества продукции, соблюдения сроков и обслуживания клиентов. Я бы дал им 6 звезд, если бы мог! 

 Для того, чтобы подключить аппарат к сжиженному баллонному газу, требуется комплект перехода Hosseven LPG KIT, который обеспечит корректное функционирование прибора. Все элементы изготовлены из прочного и долговечного материала высокого качества. Переоборудование аппарата на работу на сжиженном газе должен производить только сотрудник авторизованного сервисного центра во избежание ошибок и поломки оборудования.
Для того, чтобы подключить аппарат к сжиженному баллонному газу, требуется комплект перехода Hosseven LPG KIT, который обеспечит корректное функционирование прибора. Все элементы изготовлены из прочного и долговечного материала высокого качества. Переоборудование аппарата на работу на сжиженном газе должен производить только сотрудник авторизованного сервисного центра во избежание ошибок и поломки оборудования. Каждый конвектор снабжается инструкцией на русском языке и гарантийным талоном.
Каждый конвектор снабжается инструкцией на русском языке и гарантийным талоном.




 Также стальной теплообменник быстрее остывает, т.е. менее инертен, в результате чего требуется его более частое включение/выключение.
Также стальной теплообменник быстрее остывает, т.е. менее инертен, в результате чего требуется его более частое включение/выключение.
 Узнать больше »
Узнать больше » BW LPG в настоящее время торгуется по 53,7 норвежских крон за акцию, что составляет 6,13 доллара США при обменном курсе 8,75 доллара США к норвежской кроне.
BW LPG в настоящее время торгуется по 53,7 норвежских крон за акцию, что составляет 6,13 доллара США при обменном курсе 8,75 доллара США к норвежской кроне.

 Это привело к тому, что дивиденды за весь год составили 0,56 доллара США при дивидендной доходности примерно 10%, но инвесторы предупреждены, что BW LPG столкнулась с некоторыми неповторяющимися элементами, которые увеличили прибыль компании. Если чартерные ставки останутся стабильными и в 2022 году не возникнет единовременных элементов, нам, вероятно, придется снизить наши ожидания в отношении дивидендов за весь год.
Это привело к тому, что дивиденды за весь год составили 0,56 доллара США при дивидендной доходности примерно 10%, но инвесторы предупреждены, что BW LPG столкнулась с некоторыми неповторяющимися элементами, которые увеличили прибыль компании. Если чартерные ставки останутся стабильными и в 2022 году не возникнет единовременных элементов, нам, вероятно, придется снизить наши ожидания в отношении дивидендов за весь год. Это ускорится в 2022 году, когда ожидается поставка 18 дополнительных судов, а затем ожидаемое чистое увеличение на 38 судов в 2023 году. Транспортировка СНГ, учитывая, что количество судов, добавляемых на рынок, окажет негативное влияние на чартерные ставки и спотовые ставки для этого сегмента перевозок. Нам не нужно углубляться в историю, чтобы увидеть, что означало внезапное расширение мирового флота для компании BW LPG. В 2015 и 2016 годах их новым владельцам было передано почти 80 новых судов, и из-за перенасыщения рынка пострадали все. Как вы можете видеть на следующем изображении, EBITDA BW LPG резко упала, когда суда были доставлены, и компании потребовалось несколько лет, чтобы восстановиться. В 2016 году BW LPG также пришлось зарегистрировать убыток от обесценения в размере 144 млн долларов, поскольку рыночная стоимость судов снизилась из-за ситуации с избыточным предложением.
Это ускорится в 2022 году, когда ожидается поставка 18 дополнительных судов, а затем ожидаемое чистое увеличение на 38 судов в 2023 году. Транспортировка СНГ, учитывая, что количество судов, добавляемых на рынок, окажет негативное влияние на чартерные ставки и спотовые ставки для этого сегмента перевозок. Нам не нужно углубляться в историю, чтобы увидеть, что означало внезапное расширение мирового флота для компании BW LPG. В 2015 и 2016 годах их новым владельцам было передано почти 80 новых судов, и из-за перенасыщения рынка пострадали все. Как вы можете видеть на следующем изображении, EBITDA BW LPG резко упала, когда суда были доставлены, и компании потребовалось несколько лет, чтобы восстановиться. В 2016 году BW LPG также пришлось зарегистрировать убыток от обесценения в размере 144 млн долларов, поскольку рыночная стоимость судов снизилась из-за ситуации с избыточным предложением. За последние двенадцать месяцев компания продала несколько судов выше балансовой стоимости, и выручка от этих сделок обычно используется для выкупа акций. Мало того, что BW LPG торгуется со значительным дисконтом по сравнению с его официальной балансовой стоимостью, недавняя продажа судов, кажется, подтверждает, что балансовая стоимость кажется довольно консервативной по сравнению с рыночной стоимостью некоторых активов.
За последние двенадцать месяцев компания продала несколько судов выше балансовой стоимости, и выручка от этих сделок обычно используется для выкупа акций. Мало того, что BW LPG торгуется со значительным дисконтом по сравнению с его официальной балансовой стоимостью, недавняя продажа судов, кажется, подтверждает, что балансовая стоимость кажется довольно консервативной по сравнению с рыночной стоимостью некоторых активов. Судоходство является циклическим бизнесом, и я хочу отказаться от BW LPG до того, как увеличение предложения судов отразится на чартерных ставках. Я ожидал большего скачка по сравнению с 48 норвежскими кронами за акцию, по которым акции торговались прошлым летом, но, к счастью, за последние несколько месяцев мы получили несколько хороших дивидендов. В настоящее время у меня осталась небольшая длинная позиция по BW LPG, и, как уже упоминалось, я рассчитываю выйти из нее в ближайшем будущем.
Судоходство является циклическим бизнесом, и я хочу отказаться от BW LPG до того, как увеличение предложения судов отразится на чартерных ставках. Я ожидал большего скачка по сравнению с 48 норвежскими кронами за акцию, по которым акции торговались прошлым летом, но, к счастью, за последние несколько месяцев мы получили несколько хороших дивидендов. В настоящее время у меня осталась небольшая длинная позиция по BW LPG, и, как уже упоминалось, я рассчитываю выйти из нее в ближайшем будущем. Поскольку я твердо верю, что портфель должен состоять из комбинации акций, приносящих дивиденды, и акций роста, мои статьи будут отражать мои мысли об этой комбинации.
Поскольку я твердо верю, что портфель должен состоять из комбинации акций, приносящих дивиденды, и акций роста, мои статьи будут отражать мои мысли об этой комбинации. Пожалуйста, отключите блокировщик рекламы и обновите страницу.
Пожалуйста, отключите блокировщик рекламы и обновите страницу.

 их финансовый год 2021. Хотя это было частично связано с тем, что первые увидели значительный прирост оборотного капитала в размере 21,6 млн долларов, что помешало их поверхностному результату, тогда как вторые увидели лишь несущественную ничью в размере менее 1 млн долларов. Если бы не этот временный встречный ветер, их свободный денежный поток составил бы 9 долларов.3,8 млн в 2022 финансовом году были бы значительно выше, если бы базовый результат составил 115,4 млн долларов.
их финансовый год 2021. Хотя это было частично связано с тем, что первые увидели значительный прирост оборотного капитала в размере 21,6 млн долларов, что помешало их поверхностному результату, тогда как вторые увидели лишь несущественную ничью в размере менее 1 млн долларов. Если бы не этот временный встречный ветер, их свободный денежный поток составил бы 9 долларов.3,8 млн в 2022 финансовом году были бы значительно выше, если бы базовый результат составил 115,4 млн долларов.
 2023. Несмотря на то, что руководство фактически возвращает почти весь свой свободный денежный поток, плюс-минус немного в зависимости от временных движений оборотного капитала, они до сих пор не сформулировали какой-либо конкретной политики возврата акционеров, но, по крайней мере, они продемонстрировали общий позитивный тон при обсуждении своих перспектив. , согласно комментарию руководства, приведенному ниже.
2023. Несмотря на то, что руководство фактически возвращает почти весь свой свободный денежный поток, плюс-минус немного в зависимости от временных движений оборотного капитала, они до сих пор не сформулировали какой-либо конкретной политики возврата акционеров, но, по крайней мере, они продемонстрировали общий позитивный тон при обсуждении своих перспектив. , согласно комментарию руководства, приведенному ниже. Было бы предпочтительнее видеть четко сформулированную политику в отношении доходов акционеров, но, по крайней мере, они не исключали дальнейших дивидендов и, по-видимому, в целом выразили положительный настрой в отношении своих перспектив. Практически каждый инвестор уже слышал, что мир столкнулся со структурной нехваткой энергии, особенно усугубленной российско-украинской войной, которая лишает Европу столь необходимых поставок газа и приводит к беспрецедентным ценам на континенте. Россия сокращает их экспорт в ответ на санкции. Естественно, этот дефицит также распространился на другие энергетические рынки, такие как уголь, цена на который резко возросла в течение 2022 года, поскольку страны изо всех сил пытаются удовлетворить свои потребности в энергии.
Было бы предпочтительнее видеть четко сформулированную политику в отношении доходов акционеров, но, по крайней мере, они не исключали дальнейших дивидендов и, по-видимому, в целом выразили положительный настрой в отношении своих перспектив. Практически каждый инвестор уже слышал, что мир столкнулся со структурной нехваткой энергии, особенно усугубленной российско-украинской войной, которая лишает Европу столь необходимых поставок газа и приводит к беспрецедентным ценам на континенте. Россия сокращает их экспорт в ответ на санкции. Естественно, этот дефицит также распространился на другие энергетические рынки, такие как уголь, цена на который резко возросла в течение 2022 года, поскольку страны изо всех сил пытаются удовлетворить свои потребности в энергии. Дефицит трех основных ископаемых видов топлива, скорее всего, сохранится и в будущем, и, таким образом, я ожидаю, что в дальнейшем это приведет к повышению спроса на СНГ, поскольку потребители отдают предпочтение наиболее рентабельному источнику энергии и переключаются на него, где это возможно, особенно когда Сжиженный нефтяной газ также можно использовать для отопления и приготовления пищи, как и природный газ. Это создает прилив, который поднимает все лодки и, в свою очередь, должен повысить спрос на их суда для сжиженного нефтяного газа, поскольку большинство экспортеров и импортеров отделены океанами, как показано на приведенном ниже графике.
Дефицит трех основных ископаемых видов топлива, скорее всего, сохранится и в будущем, и, таким образом, я ожидаю, что в дальнейшем это приведет к повышению спроса на СНГ, поскольку потребители отдают предпочтение наиболее рентабельному источнику энергии и переключаются на него, где это возможно, особенно когда Сжиженный нефтяной газ также можно использовать для отопления и приготовления пищи, как и природный газ. Это создает прилив, который поднимает все лодки и, в свою очередь, должен повысить спрос на их суда для сжиженного нефтяного газа, поскольку большинство экспортеров и импортеров отделены океанами, как показано на приведенном ниже графике.

 результат 3,66 в те же два момента времени, в основном из-за того, что последний результат показывает наращивание оборотного капитала, потому что в случае удаления их предыдущий результат на конец 2022 финансового года был бы 3,09. К счастью, оба их последних результата теперь находятся на умеренной территории между 2,01 и 3,50, что не вызывает беспокойства с точки зрения платежеспособности и, таким образом, не препятствует их способности безопасно возвращать весь свой свободный денежный поток.
результат 3,66 в те же два момента времени, в основном из-за того, что последний результат показывает наращивание оборотного капитала, потому что в случае удаления их предыдущий результат на конец 2022 финансового года был бы 3,09. К счастью, оба их последних результата теперь находятся на умеренной территории между 2,01 и 3,50, что не вызывает беспокойства с точки зрения платежеспособности и, таким образом, не препятствует их способности безопасно возвращать весь свой свободный денежный поток. в обозримом будущем. После рефинансирования долга в первом квартале 2023 финансового года они теперь видят более плавный график погашения долга с небольшими суммами на ближайшие четыре года, как показано на графике, приведенном ниже. Это упрощает управление их финансами и, таким образом, помогает обеспечить доходность для акционеров в ближайшие годы, а также помогает снизить их устойчивость к любым неожиданным спадам.
в обозримом будущем. После рефинансирования долга в первом квартале 2023 финансового года они теперь видят более плавный график погашения долга с небольшими суммами на ближайшие четыре года, как показано на графике, приведенном ниже. Это упрощает управление их финансами и, таким образом, помогает обеспечить доходность для акционеров в ближайшие годы, а также помогает снизить их устойчивость к любым неожиданным спадам. После этой статьи и их положительного прогноза я считаю, что повышение моего рейтинга покупок до сильного рейтинга покупок теперь уместно.
После этой статьи и их положительного прогноза я считаю, что повышение моего рейтинга покупок до сильного рейтинга покупок теперь уместно.

 Проверьте правильность применения и спецификации/размеры. Любое использование этой перекрестной ссылки осуществляется на риск установщика.
Проверьте правильность применения и спецификации/размеры. Любое использование этой перекрестной ссылки осуществляется на риск установщика.
 Малые отдаленные острова США Виргинские островаУзбекистанВануатуВатиканВенесуэлаВьетнамУоллис и ФутунаЗападная СахараЙеменЗамбияЗимбабве
Малые отдаленные острова США Виргинские островаУзбекистанВануатуВатиканВенесуэлаВьетнамУоллис и ФутунаЗападная СахараЙеменЗамбияЗимбабве
 4
4 Расчет стоимости доставки производится
Расчет стоимости доставки производится прям. 1.4кВт 51.7см38.3кг HT21 на сайте носят информационный
прям. 1.4кВт 51.7см38.3кг HT21 на сайте носят информационный союз Champion триммеры бенз.СЗИК`22.pdf
союз Champion триммеры бенз.СЗИК`22.pdf Каждая модель этого бренда отличается от аналогов простотой устройства, что значительно облегчает ее обслуживание и ремонт. Низкие цены на большинство садовых инструментов от американского производителя делают их доступными практически для любого желающего садовода.
Каждая модель этого бренда отличается от аналогов простотой устройства, что значительно облегчает ее обслуживание и ремонт. Низкие цены на большинство садовых инструментов от американского производителя делают их доступными практически для любого желающего садовода.
 За запуск встроенного ДВС в стандартном устройстве модели отвечает стандартный ручной стартер.
За запуск встроенного ДВС в стандартном устройстве модели отвечает стандартный ручной стартер.
 Благодаря небольшому весу мотокосу можно поднять для удаления вьющихся диких растений.
Благодаря небольшому весу мотокосу можно поднять для удаления вьющихся диких растений.
 Тем не менее, некоторые ее элементы со временем изнашиваются.
Тем не менее, некоторые ее элементы со временем изнашиваются.
 За защиту оператора в устройстве модели отвечает пластиковый кожух. Для удобства во время эксплуатации производитель изначально предусмотрел в стандартном заводском оснащении этого бытового триммера регулируемый наплечный ремень и D-образную рукоятку.
За защиту оператора в устройстве модели отвечает пластиковый кожух. Для удобства во время эксплуатации производитель изначально предусмотрел в стандартном заводском оснащении этого бытового триммера регулируемый наплечный ремень и D-образную рукоятку.

 д.
д. Свеча зажигания
Свеча зажигания
 Изображения могут не отражать инвентарь продавца и/или характеристики товара. Руководство оператора Заявление об отказе от ответственности: Опубликованное руководство оператора предназначено для общего ознакомления и использования. Чтобы обеспечить загрузку руководства по эксплуатации, относящегося к вашему устройству, нам требуются модель и серийный номер. Скорость Отказ от ответственности: Фактическая скорость автомобиля зависит от нагрузки, использования и условий окружающей среды. Аккумулятор Отказ от ответственности: Производительность аккумулятора и продукта с питанием от аккумулятора зависит от нагрузки, использования и условий окружающей среды. Отказ от ответственности в отношении программного обеспечения: Программное обеспечение, доступное на веб-сайтах Компании, предоставляется на условиях «как есть» без каких-либо явных или подразумеваемых гарантий. Загрузка и использование любого программного обеспечения осуществляется пользователем на свой страх и риск.
Изображения могут не отражать инвентарь продавца и/или характеристики товара. Руководство оператора Заявление об отказе от ответственности: Опубликованное руководство оператора предназначено для общего ознакомления и использования. Чтобы обеспечить загрузку руководства по эксплуатации, относящегося к вашему устройству, нам требуются модель и серийный номер. Скорость Отказ от ответственности: Фактическая скорость автомобиля зависит от нагрузки, использования и условий окружающей среды. Аккумулятор Отказ от ответственности: Производительность аккумулятора и продукта с питанием от аккумулятора зависит от нагрузки, использования и условий окружающей среды. Отказ от ответственности в отношении программного обеспечения: Программное обеспечение, доступное на веб-сайтах Компании, предоставляется на условиях «как есть» без каких-либо явных или подразумеваемых гарантий. Загрузка и использование любого программного обеспечения осуществляется пользователем на свой страх и риск. Профессиональные продукты: 9Коммерческие продукты Cub Cadet 0192 предназначены для профессионального использования. UTV: Внедорожники Cub Cadet (UTV) предназначены только для взрослых. Более подробную информацию см. в руководстве по эксплуатации и на предупреждающих табличках, размещенных на самом автомобиле. Отказ от ответственности по электронной почте: Зарегистрируйтесь, чтобы получать сообщения об услугах, продуктах и специальных предложениях. Вы можете отменить подписку в любое время. Пожалуйста, обратитесь к нашему .
Профессиональные продукты: 9Коммерческие продукты Cub Cadet 0192 предназначены для профессионального использования. UTV: Внедорожники Cub Cadet (UTV) предназначены только для взрослых. Более подробную информацию см. в руководстве по эксплуатации и на предупреждающих табличках, размещенных на самом автомобиле. Отказ от ответственности по электронной почте: Зарегистрируйтесь, чтобы получать сообщения об услугах, продуктах и специальных предложениях. Вы можете отменить подписку в любое время. Пожалуйста, обратитесь к нашему .

 на голову (или колесо к колесу) с конкурентами.
на голову (или колесо к колесу) с конкурентами. Вот несколько способов обойти эти распространенные проблемы.
Вот несколько способов обойти эти распространенные проблемы. В большинстве районов страны будет сложнее найти сервисный центр, который отремонтирует аккумуляторную или сетевую газонокосилку. (Калифорния может быть исключением.) Кроме того, центры, которые ремонтируют аккумуляторные (или сетевые) косилки, часто работают только с определенными брендами.
В большинстве районов страны будет сложнее найти сервисный центр, который отремонтирует аккумуляторную или сетевую газонокосилку. (Калифорния может быть исключением.) Кроме того, центры, которые ремонтируют аккумуляторные (или сетевые) косилки, часто работают только с определенными брендами.
 технические характеристики)
технические характеристики)  Но захотели бы вы протащить удлинитель даже через четверть акра? Для некоторых домовладельцев сетевая косилка идеально подходит даже для газона большего размера. Это зависит от личных предпочтений и планировки вашего газона (холмы, ровная поверхность, расположение розетки).
Но захотели бы вы протащить удлинитель даже через четверть акра? Для некоторых домовладельцев сетевая косилка идеально подходит даже для газона большего размера. Это зависит от личных предпочтений и планировки вашего газона (холмы, ровная поверхность, расположение розетки). Чем выше сила тока, тем больше мощности у вас будет для скашивания труднопроходимых участков и высокой травы.
Чем выше сила тока, тем больше мощности у вас будет для скашивания труднопроходимых участков и высокой травы. Некоторые машины считаются одноразовыми.
Некоторые машины считаются одноразовыми. Вот некоторые из новых функций, которые можно найти в некоторых современных газонокосилках:
Вот некоторые из новых функций, которые можно найти в некоторых современных газонокосилках:
 Каков срок службы электрических газонокосилок?
Каков срок службы электрических газонокосилок?  Безопасно ли косить мокрую траву электрической газонокосилкой?
Безопасно ли косить мокрую траву электрической газонокосилкой? 


 Вопрос решен приобретением универсального инструмента : Почему выбрана мотоблок к 700, данная изготовитель изготавливает инструмент на одном заводе, а не с разных заводов запчасти, которые часто подгонять нужно. В общем и к качеству материалов, качеству сборки, удобству пользования и дизайну, проблем не имею.
Вопрос решен приобретением универсального инструмента : Почему выбрана мотоблок к 700, данная изготовитель изготавливает инструмент на одном заводе, а не с разных заводов запчасти, которые часто подгонять нужно. В общем и к качеству материалов, качеству сборки, удобству пользования и дизайну, проблем не имею. Покупал на али, со скидками, купоном и промокодом. Что мы есть за эти деньги? Сам мотоблок к 700 очень компактный, корпус сбитый, прорезиненый, не чего не скрипит, не люфтит. В совокупности все устраивает, качества хватает с головой. Тестировал пока мало. Позже дополню отзыв по эксплуатации.
Покупал на али, со скидками, купоном и промокодом. Что мы есть за эти деньги? Сам мотоблок к 700 очень компактный, корпус сбитый, прорезиненый, не чего не скрипит, не люфтит. В совокупности все устраивает, качества хватает с головой. Тестировал пока мало. Позже дополню отзыв по эксплуатации.

 Служба качества контролирует процесс производства на каждом этапе.
Служба качества контролирует процесс производства на каждом этапе. 5
5 -час
-час 00-12
00-12 27 МБ)
27 МБ)
 США
США 
 Указанная величина приведена для эксплуатации насоса на высоте при температуре окружающей среды и перекачиваемой жидкости 20°С и при нулевой альтитуде (высоте над уровнем моря). В реальных условиях эксплуатации высота подъема воды насосом может быть меньше.
Указанная величина приведена для эксплуатации насоса на высоте при температуре окружающей среды и перекачиваемой жидкости 20°С и при нулевой альтитуде (высоте над уровнем моря). В реальных условиях эксплуатации высота подъема воды насосом может быть меньше. 
 00₽
00₽ При этом потребление электроэнергии насосной станцией пропорционально скорости вращения вала гидравлики, за счет чего достигается значительная экономия электроэнергии (до 40-50%).**
При этом потребление электроэнергии насосной станцией пропорционально скорости вращения вала гидравлики, за счет чего достигается значительная экономия электроэнергии (до 40-50%).**



 : 40
: 40



 с.]
с.]